使用 PyTorch 进行深度学习(9 天迷你课程)
在这个由 9 部分组成的速成课程中,您将通过易于使用且功能强大的 PyTorch 库在 Python 中发现应用深度学习。这个迷你课程面向已经熟悉 Python 编程并了解机器学习基本概念的从业者
推荐:将NSDT场景编辑器加入你的3D工具链
3D工具集:NSDT简石数字孪生
使用 PyTorch 进行深度学习(9 天迷你课程)
深度学习是一个引人入胜的研究领域,这些技术在一系列具有挑战性的机器学习问题上取得了世界级的成果。开始深度学习可能很困难。
在这个由 9 部分组成的速成课程中,您将通过易于使用且功能强大的 PyTorch 库在 Python 中发现应用深度学习。这个迷你课程面向已经熟悉 Python 编程并了解机器学习基本概念的从业者。让我们开始吧。
这是一篇长而有用的帖子。您可能希望将其打印出来。
让我们开始吧。

这个迷你课程是为谁准备的?
在我们开始之前,让我们确保您在正确的位置。下面的列表提供了一些关于本课程设计对象的一般准则。如果您不完全匹配这些要点,请不要惊慌,您可能只需要在一个或另一个领域复习以跟上。
- 知道如何编写少量代码的开发人员。这意味着使用Python完成工作并知道如何在工作站上设置生态系统(先决条件)对您来说并不是什么大问题。这并不意味着您是向导编码人员,但确实意味着您不怕安装软件包和编写脚本。
- 懂一点机器学习的开发人员。这意味着您了解机器学习的基础知识,例如交叉验证、一些算法和偏差-方差权衡。这并不意味着你是一个机器学习博士,只是你知道地标或知道在哪里查找它们。
这门迷你课程不是关于深度学习的教科书。
它将带您从一个懂一点 Python 机器学习的开发人员转变为能够获得结果并将深度学习的强大功能带入您自己的项目的开发人员。
迷你课程概述
这个迷你课程分为9个部分。
每节课的设计目的是让普通开发人员大约 30 分钟。你可能会更快地完成一些,而其他的你可能会选择更深入,花更多的时间。
您可以根据需要快速或缓慢地完成每个部分。一个舒适的时间表可能是在九天内每天完成一节课。强烈推荐。
您将在接下来的 9 节课中涵盖的主题如下:
- 第 1 课:PyTorch 简介。
- 第 2 课:构建您的第一个多层感知器模型
- 第 3 课:训练 PyTorch 模型
- 第 4 课:使用 PyTorch 模型进行推理
- 第 5 课:从火炬视觉加载数据
- 第 6 课:使用 PyTorch DataLoader
- 第 7 课:卷积神经网络
- 第 8 课:训练图像分类器
- 第 9 课:使用 GPU 进行训练
这会很有趣。
不过,你将不得不做一些工作,一点阅读,一点研究和一点编程。你想学习深度学习吗?
在评论中发布您的结果;我会为你加油!
忍耐一下;不要放弃。
第 01 课:PyTorch 简介
PyTorch是由Facebook创建和发布的用于深度学习计算的Python库。它的根源来自早期的库 Torch 7,但完全重写。
它是两个最受欢迎的深度学习库之一。PyTorch 是一个完整的库,能够训练深度学习模型以及在推理模式下运行模型,并支持使用 GPU 进行更快的训练和推理。这是一个我们不能忽视的平台。
在本课中,您的目标是安装 PyTorch 熟悉 PyTorch 程序中使用的符号表达式的语法。
例如,您可以使用 安装 PyTorch。在撰写本文时,最新版本的 PyTorch 是 2.0。每个平台都预构建了PyTorch,包括Windows,Linux和macOS。对于有效的Python环境,应该为您处理这个问题,以便为您提供平台中的最新版本。pippip
除了 PyTorch,还有通常与 PyTorch 一起使用的库。它提供了许多有用的功能来帮助计算机视觉项目。torchvision
1 | sudo pip install torch torchvision |
下面列出了一个可以用作起点的 PyTorch 程序的小示例:
1 2 3 4 5 6 7 8 | # Example of PyTorch library import torch # declare two symbolic floating-point scalars a = torch.tensor(1.5) b = torch.tensor(2.5) # create a simple symbolic expression using the add function c = torch.add(a, b) print(c) |
在 PyTorch 主页上了解有关 PyTorch 的更多信息。
您的任务
重复上面的代码以确保您正确安装了 PyTorch。您还可以通过运行以下 Python 代码行来检查您的 PyTorch 版本:
1 2 | import torch print(torch.__version__) |
在下一课中,您将使用 PyTorch 构建神经网络模型。
第 02 课:构建您的第一个多层感知器模型
深度学习是关于构建大规模神经网络。神经网络的最简单形式称为多层感知器模型。神经网络的构建块是人工神经元或感知器。这些是简单的计算单元,具有加权输入信号并使用激活函数产生输出信号。
感知器被排列成网络。一排感知器称为一个层,一个网络可以有多个层。网络中感知器的体系结构通常称为网络拓扑。配置完成后,需要在数据集上训练神经网络。神经网络的经典且仍然首选的训练算法称为随机梯度下降。
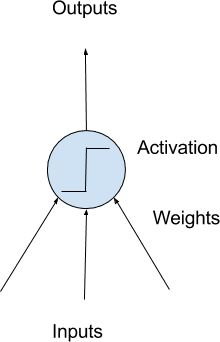
简单神经元的模型
PyTorch 允许您在很少的代码行中开发和评估深度学习模型。
在下文中,您的目标是使用 PyTorch 开发您的第一个神经网络。使用 UCI 机器学习存储库中的标准二进制(两类)分类数据集,如皮马印第安人数据集。
为了简单起见,网络模型只是几层完全连接的感知器。在此特定模型中,数据集具有 12 个输入或预测变量,输出是单个值 0 或 1。因此,网络模型应具有 12 个输入(第一层)和 1 个输出(最后一层)。您的第一个模型将按如下方式构建:
1 2 3 4 5 6 7 8 9 10 11 | import torch.nn as nn model = nn.Sequential( nn.Linear(8, 12), nn.ReLU(), nn.Linear(12, 8), nn.ReLU(), nn.Linear(8, 1), nn.Sigmoid() ) print(model) |
这是一个具有 3 个全连接层的网络。每个层都是在 PyTorch 中使用的语法创建的,第一个参数是层的输入数,第二个参数是输出数。在每层之间,使用整流线性激活,但在输出端,应用sigmoid激活,使得输出值介于0和1之间。这是一个典型的网络。深度学习模型就是在一个模型中有很多这样的层。nn.Linear(x, y)
您的任务
重复上述代码并观察打印的模型输出。尝试在上面的第一层之后添加另一个输出 20 个值的图层。您应该更改什么行以适应此添加?Linearnn.Linear(12, 8)
在下一课中,您将了解如何训练此模型。
第 03 课:训练 PyTorch 模型
在 PyTorch 中构建神经网络并不能说明您应该如何为特定作业训练模型。事实上,正如超参数所描述的那样,这方面有很多变化。在 PyTorch 或一般的所有深度学习模型中,您需要决定如何训练模型:
- 什么是数据集,特别是输入和目标的外观
- 什么是评估模型与数据的拟合优度的损失函数
- 训练模型的优化算法是什么,优化算法的参数,如学习率和训练的迭代次数
在上一课程中,使用了皮马印第安人数据集,所有输入都是数字。这将是最简单的情况,因为您不需要对数据进行任何预处理,因为神经网络可以轻松处理数字。
由于这是一个二元分类问题,损失函数应该是二元交叉熵。这意味着分类结果的模型输出目标为 0 或 1。但实际上,该模型可能会输出介于两者之间的任何内容。越接近目标值越好(即损失越低)。
梯度下降是优化神经网络的算法。梯度下降有很多变化,亚当是最常用的变体之一。
实现上述所有内容,以及上一课中构建的模型,以下是训练过程的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | import numpy as np import torch import torch.nn as nn import torch.optim as optim dataset = np.loadtxt('pima-indians-diabetes.csv', delimiter=',') X = dataset[:,0:8] y = dataset[:,8] X = torch.tensor(X, dtype=torch.float32) y = torch.tensor(y, dtype=torch.float32).reshape(-1, 1) loss_fn = nn.BCELoss() # binary cross-entropy optimizer = optim.Adam(model.parameters(), lr=0.001) n_epochs = 100 batch_size = 10 for epoch in range(n_epochs): for i in range(0, len(X), batch_size): Xbatch = X[i:i+batch_size] y_pred = model(Xbatch) ybatch = y[i:i+batch_size] loss = loss_fn(y_pred, ybatch) optimizer.zero_grad() loss.backward() optimizer.step() print(f'Finished epoch {epoch}, latest loss {loss}') |
上面的 for 循环是获取一批数据并馈送到模型中。然后观察模型的输出并计算损失函数。基于损失函数,优化器将微调模型一步,以便它可以更好地匹配训练数据。经过许多更新步骤后,模型应该足够接近训练数据,以便它可以高精度地预测目标。
您的任务
运行上面的训练循环,观察损失如何随着训练循环的进行而减少。
在下一课中,您将看到如何使用经过训练的模型。
第 04 课:使用 PyTorch 模型进行推理
经过训练的神经网络模型是记住输入和目标如何关联的模型。然后,该模型可以预测给定另一个输入的目标。
在 PyTorch 中,经过训练的模型可以像函数一样运行。假设您在上一课中训练了模型,您可以简单地使用它,如下所示:
1 2 3 4 | i = 5 X_sample = X[i:i+1] y_pred = model(X_sample) print(f"{X_sample[0]} -> {y_pred[0]}") |
但实际上,运行推理的更好方法如下:
1 2 3 4 5 6 | i = 5 X_sample = X[i:i+1] model.eval() with torch.no_grad(): y_pred = model(X_sample) print(f"{X_sample[0]} -> {y_pred[0]}") |
某些模型在训练和推理之间的行为会有所不同。的行是向模型发出信号,表明意图是运行模型进行推理。这条线是为了创建一个运行模型的上下文,这样 PyTorch 就知道不需要计算梯度。这可以消耗更少的资源。model.eval()with torch.no_grad()
这也是评估模型的方法。模型输出一个介于 0 和 1 之间的 S 形值。您可以通过将值舍入到最接近的整数(即布尔标签)来解释该值。比较舍入后的预测与目标匹配的频率,可以为模型分配准确率百分比,如下所示:
1 2 3 4 5 | model.eval() with torch.no_grad(): y_pred = model(X) accuracy = (y_pred.round() == y).float().mean() print(f"Accuracy {accuracy}") |
您的任务
运行上面的代码,看看你得到的准确性是多少。您应该达到大约 75%。
在下一课中,您将了解火炬视觉。
第 05 课:从火炬视觉加载数据
Torchvision是PyTorch的姊妹图书馆。在此库中,有专门用于图像和计算机视觉的功能。如您所料,有一些功能可以帮助您阅读图像或调整对比度。但可能最重要的是提供一个简单的界面来获取一些图像数据集。
在下一课中,您将构建一个深度学习模型来对小图像进行分类。这是一个模型,允许您的计算机查看图像上的内容。正如您在前面的课程中看到的,拥有用于训练模型的数据集非常重要。您将使用的数据集是 CIFAR-10。它是一个包含 10 个不同对象的数据集。还有一个更大的数据集叫做CIFAR-100。
CIFAR-10数据集可以从互联网上下载。但是,如果您安装了火炬视觉,则只需执行以下操作:
1 2 3 4 5 6 7 8 9 10 11 | import matplotlib.pyplot as plt import torchvision trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True) fig, ax = plt.subplots(4, 6, sharex=True, sharey=True, figsize=(12,8)) for i in range(0, 24): row, col = i//6, i%6 ax[row][col].imshow(trainset.data[i]) plt.show() |
该函数可帮助您将 CIFAR-10 数据集下载到本地目录。数据集分为训练集和测试集。因此,上面的两行是得到它们。然后,从下载的数据集中绘制前 24 张图像。数据集中的每个图像都是以下其中一项的 32×32 像素图片:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、轮船或卡车。torchvision.datasets.CIFAR10
您的任务
根据上面的代码,你能找到一种方法来分别计算训练集和测试集中总共有多少张图像吗?
在下一课中,您将学习如何使用 PyTorch DataLoader。
第 06 课:使用 PyTorch DataLoader
上一课中的 CIFAR-10 图像确实采用 numpy 数组的格式。但是对于 PyTorch 模型的使用,它需要在 PyTorch 张量中。将 numpy 数组转换为 PyTorch 张量并不困难,但在训练循环中,您仍然需要批量划分数据集。PyTorch DataLoader 可以帮助您使此过程更顺畅。
返回到上一课中加载的 CIFAR-10 数据集,您可以执行以下操作以获得相同的效果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import matplotlib.pyplot as plt import torchvision import torch from torchvision.datasets import CIFAR10 transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()]) trainset = CIFAR10(root='./data', train=True, download=True, transform=transform) testset = CIFAR10(root='./data', train=False, download=True, transform=transform) batch_size = 24 trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True) testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=True) fig, ax = plt.subplots(4, 6, sharex=True, sharey=True, figsize=(12,8)) for images, labels in trainloader: for i in range(batch_size): row, col = i//6, i%6 ax[row][col].imshow(images[i].numpy().transpose([1,2,0])) break # take only the first batch plt.show() |
在此代码中,使用参数创建,以便在提取数据时将数据转换为 PyTorch 张量。这是在它后面的行中执行的。该对象是一个 Python 可迭代对象,您可以提取输入(图像)和目标(整数类标签)。在这种情况下,您将批大小设置为 24 并迭代第一个批次。然后显示批处理中的每个图像。trainsettransformDataLoaderDataLoader
您的任务
运行上面的代码,并与上一课中生成的 matplotlib 输出进行比较。您应该看到输出不同。为什么?行中有一个争论导致了差异。你能确定是哪一个吗?DataLoader
在下一课中,您将学习如何构建深度学习模型来对 CIFAR-10 数据集中的图像进行分类。
第07课:卷积神经网络
图像是 2D 结构。您可以通过展平化它们轻松地将它们转换为 1D 向量,并构建神经网络模型来对它们进行分类。但众所周知,保留 2D 结构会更合适,因为分类是关于图像中的内容,这是平移不变的。
图像处理神经网络的标准方法是使用卷积层。使用卷积层的神经网络称为卷积神经网络。示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import torch.nn as nn model = nn.Sequential( nn.Conv2d(3, 32, kernel_size=(3,3), stride=1, padding=1), nn.ReLU(), nn.Dropout(0.3), nn.Conv2d(32, 32, kernel_size=(3,3), stride=1, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=(2, 2)), nn.Flatten(), nn.Linear(8192, 512), nn.ReLU(), nn.Dropout(0.5), nn.Linear(512, 10) ) print(model) |
在上面,我们多次使用了层,以及激活。卷积层用于从图像中学习和提取特征。你添加的卷积层越多,网络就可以学习到更多的高级特征。最终,您将使用池化层(上图)对提取的特征进行分组,将它们展平为一个向量,然后将其传递给多层感知器网络进行最终分类。这是图像分类模型的常用结构。Conv2dReLUMaxPool2d
您的任务
运行上面的代码以确保您可以正确创建模型。您没有在模型中指定输入图像大小,但实际上它在 RGB 中固定为 32×32 像素(即 3 个颜色通道)。这在网络中的什么位置固定?
在下一课中,您将使用上一课中的数据加载程序来训练上面的模型。
第 08 课:训练图像分类器
结合为 CIFAR-10 数据集创建的 DataLoader,您可以使用以下训练循环在上一课中训练卷积神经网络:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | import torch.nn as nn import torch.optim as optim loss_fn = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) n_epochs = 20 for epoch in range(n_epochs): model.train() for inputs, labels in trainloader: y_pred = model(inputs) loss = loss_fn(y_pred, labels) optimizer.zero_grad() loss.backward() optimizer.step() acc = 0 count = 0 model.eval() with torch.no_grad(): for inputs, labels in testloader: y_pred = model(inputs) acc += (torch.argmax(y_pred, 1) == labels).float().sum() count += len(labels) acc /= count print("Epoch %d: model accuracy %.2f%%" % (epoch, acc*100)) |
这将需要一段时间才能运行,您应该看到生成的模型可以达到不低于70%的精度。
此模型是一个多类分类网络。输出不是一个,而是许多分数,每个班级一个。我们认为分数越高,模型认为图像属于某个类的置信度就越高。因此,使用的损失函数是交叉熵,即二进制交叉熵的多类版本。
在上面的训练循环中,您应该会看到在前面的课程中学到的很多元素。包括在模型中的训练和推理模式之间切换、使用上下文和计算准确性。torch.no_grad()
您的任务
阅读上面的代码以确保您了解它的作用。运行此代码以观察随着训练的进行而提高的准确性。您达到的最终精度是多少?
在下一课中,您将学习如何使用 GPU 来加速同一模型的训练。
第 09 课:使用 GPU 进行训练
您在上一课中执行的模型训练应该需要一段时间。如果您有受支持的 GPU,则可以大大加快训练速度。
在 PyTorch 中使用 GPU 的方法是在执行之前将模型和数据发送到 GPU。然后,您可以选择从 GPU 发回结果,或直接在 GPU 中执行评估。
修改上一课中的代码以使用 GPU 并不困难。以下是应该做的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | import torch.nn as nn import torch.optim as optim device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device) loss_fn = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) n_epochs = 20 for epoch in range(n_epochs): model.train() for inputs, labels in trainloader: y_pred = model(inputs.to(device)) loss = loss_fn(y_pred, labels.to(device)) optimizer.zero_grad() loss.backward() optimizer.step() acc = 0 count = 0 model.eval() with torch.no_grad(): for inputs, labels in testloader: y_pred = model(inputs.to(device)) acc += (torch.argmax(y_pred, 1) == labels.to(device)).float().sum() count += len(labels) acc /= count print("Epoch %d: model accuracy %.2f%%" % (epoch, acc*100)) |
所做的更改如下:检查 GPU 是否可用并相应地设置。然后将模型发送到设备。当输入(即一批图像)传递给模型时,应首先将其发送到相应的设备。由于模型输出也将在那里,因此损失计算或精度计算也应首先将目标发送到GPU。device
由3D建模学习工作室 翻译整理,转载请注明出处!