使用 PyTorch 创建您的第一个 ML 模型
通过从头开始构建分类模型来学习 PyTorch 基础知识。

推荐:使用NSDT编辑器快速搭建3D应用场景
赋予动机
PyTorch是使用最广泛的基于Python的深度学习框架。它为所有机器学习体系结构和数据管道提供了巨大的支持。在本文中,我们将介绍所有框架基础知识,以帮助您开始实现算法。
所有机器学习实现都有 4 个主要步骤:
- 数据处理
- 模型架构
- 训练循环
- 评估
我们在 PyTorch 中实现我们自己的 MNIST 图像分类模型时会完成所有这些步骤。这将使您熟悉机器学习项目的一般流程。
进口
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
# Using MNIST dataset provided by PyTorch
from torchvision.datasets.mnist import MNIST
import torchvision.transforms as transforms
# Import Model implemented in a different file
from model import Classifier
import matplotlib.pyplot as plttorch.nn 模块提供对神经网络架构的支持,并具有针对流行层(如密集层、卷积神经网络等)的内置实现。
torch.optim 为优化器提供了实现,如随机梯度下降和 Adam。
其他实用程序模块可用于数据处理支持和转换。稍后我们将更详细地介绍每个。
声明超参数
在适当的情况下,将进一步解释每个超参数。但是,最佳做法是在文件顶部声明它们,以便于更改和理解。
INPUT_SIZE = 784 # Flattened 28x28 images
NUM_CLASSES = 10 # 0-9 hand-written digits.
BATCH_SIZE = 128 # Using Mini-Batches for Training
LEARNING_RATE = 0.01 # Opitimizer Step
NUM_EPOCHS = 5 # Total Training Epochs数据加载和转换
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: torch.flatten(x))
])
train_dataset = MNIST(root=".data/", train=True, download=True, transform=data_transforms)
test_dataset = MNIST(root=".data/", train=False, download=True, transform=data_transforms)MNIST是一个流行的图像分类数据集,默认在PyTorch中提供。它由从10到0的9个手写数字的灰度图像组成。每个图像的大小为 28 x 28 像素,数据集包含 60000 张训练图像和 10000 张测试图像。
我们分别加载训练数据集和测试数据集,由 MNIST 初始化函数中的 train 参数表示。根参数声明要在其中下载数据集的目录。
但是,我们还传递了一个额外的转换参数。对于 PyTorch,所有输入和输出都应该是 Torch.Tensor 格式。这相当于 numpy 中的 numpy.ndarray。这种张量格式为数据操作提供了额外的支持。但是,我们从中加载的 MNIST 数据位于 PIL 中。图像格式。我们需要将图像转换为兼容 PyTorch 的张量。因此,我们传递以下转换:
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: torch.flatten(x))
])ToTensor() 变换将图像转换为张量格式。接下来,我们传递一个额外的 Lambda 转换。Lambda 函数允许我们实现自定义转换。在这里,我们声明一个函数来扁平化输入。图像的大小为 28x28,但是,我们将它们展平,即将它们转换为大小为 28x28 或 784 的一维数组。当我们稍后实现我们的模型时,这将很重要。
撰写函数按顺序组合所有转换。首先,将数据转换为张量格式,然后展平为一维数组。
将数据分成几批
出于计算和训练目的,我们不能一次将完整的数据集传递到模型中。我们需要将数据集划分为小批量,这些批次将按顺序提供给模型。这允许更快的训练,并为我们的数据集增加随机性,这有助于稳定的训练。
PyTorch 为批处理数据提供了内置支持。来自火炬的数据加载器类。UTILS模块可以创建成批的数据,给定一个Torch数据集模块。如上所述,我们已经加载了数据集。
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)我们将数据集传递给我们的数据加载器,并将我们的batch_size超参数作为初始化参数。这将创建一个可迭代的数据加载器,因此我们可以使用简单的 for 循环轻松迭代每个批处理。
我们最初的图像大小为(784,),带有单个相关标签。然后,批处理将不同的图像和标签组合成一个批处理。例如,如果我们的批大小为 64,则批次中的输入大小将变为 (64, 784),并且每个批次将有 64 个关联的标签。
我们还对训练批次进行洗牌,这会更改每个时期的训练批次中的图像。它允许稳定的训练和更快的模型参数收敛。
定义我们的分类模型
我们使用由 3 个隐藏层组成的简单实现。虽然简单,但这可以让您大致了解如何组合不同的层以实现更复杂的实现。
如上所述,我们有一个大小为 (784, ) 的输入张量和 10 个不同的输出类,0-9 的每个数字对应一个。
** 对于模型实现,我们可以忽略批处理维度。
import torch
import torch.nn as nn
class Classifier(nn.Module):
def __init__(
self,
input_size:int,
num_classes:int
) -> None:
super().__init__()
self.input_layer = nn.Linear(input_size, 512)
self.hidden_1 = nn.Linear(512, 256)
self.hidden_2 = nn.Linear(256, 128)
self.output_layer = nn.Linear(128, num_classes)
self.activation = nn.ReLU()
def forward(self, x):
# Pass Input Sequentially through each dense layer and activation
x = self.activation(self.input_layer(x))
x = self.activation(self.hidden_1(x))
x = self.activation(self.hidden_2(x))
return self.output_layer(x)首先,模型必须继承自 torch.nn.Module 类。这为神经网络架构提供了基本功能。然后,我们必须实现两种方法,__init__和转发。
在 __init__ 方法中,我们声明模型将使用的所有层。我们使用 PyTorch 提供的线性(也称为密集)层。第一层将输入映射到512个神经元。我们可以将input_size作为模型参数传递,因此我们以后也可以将其用于不同大小的输入。第二层将512个神经元映射到256个神经元。第三个隐藏层将前一层的 256 个神经元映射到 128 个神经元。然后,最后一层最终减小到输出大小。我们的输出大小将是大小为 (10, ) 的张量,因为我们预测了十个不同的数字。
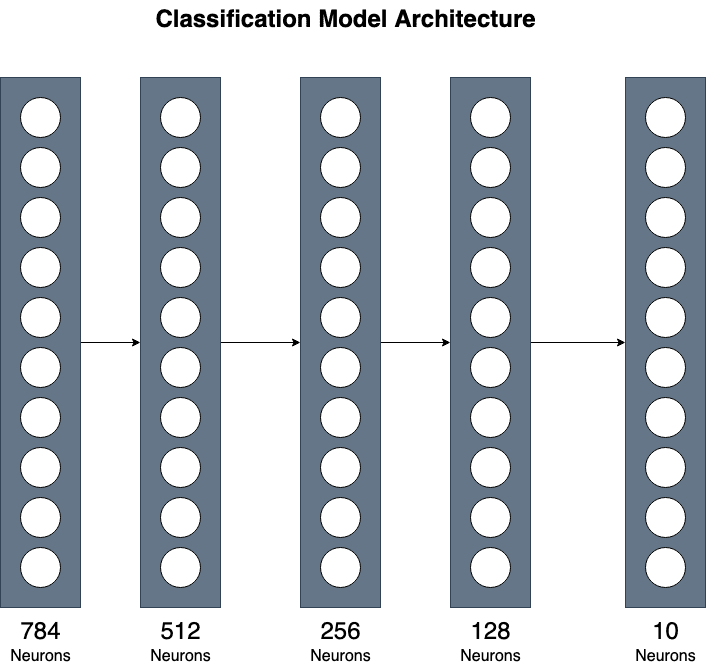
图片来源:作者
此外,我们在模型中初始化了一个ReLU激活层以实现非线性。
转发函数接收图像,我们提供用于处理输入的代码。我们使用声明的层,并按顺序将输入传递到每一层,中间有一个 ReLU 激活层。
在我们的主代码中,我们可以初始化模型,为其提供数据集的输入和输出大小。
model = Classifier(input_size=784, num_classes=10)
model.to(DEVICE)初始化后,我们更改模型设备(可以是 CUDA GPU 或 CPU)。我们在初始化超参数时检查了我们的设备。现在,我们必须手动更改张量和模型层的设备。
训练循环
首先,我们必须声明我们的损失函数和优化器,它们将用于优化我们的模型参数。
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)首先,我们必须声明我们的损失函数和优化器,它们将用于优化我们的模型参数。
我们使用主要用于多标签分类模型的交叉熵损失。它首先将 softmax 应用于预测,并计算给定的目标标签和预测值。
Adam 优化器是最常用的优化器函数,它允许稳定的梯度下降到收敛。它是当今的默认优化器选择,并提供令人满意的结果。我们将模型参数作为参数传递,该参数表示将要优化的权重。
对于我们的训练循环,我们会逐步构建并在获得理解时填补缺失的部分。
作为起点,我们多次迭代整个数据集(称为 epoch),每次都优化我们的模型。但是,我们已将数据分成几批。然后,对于每个纪元,我们还必须迭代每个批次。其代码如下所示:
for epoch in range(NUM_EPOCHS):
for batch in iter(train_dataloader):
# Train the Model for each batch.
现在,我们可以在给定单个输入批处理的情况下训练模型。我们的批次由图像和标签组成。首先,我们必须将两者分开。我们的模型只需要图像作为输入来进行预测。然后,我们将预测与真实标签进行比较,以估计模型的性能。
for epoch in range(NUM_EPOCHS):
for batch in iter(train_dataloader):
images, labels = batch # Separate inputs and labels
# Convert Tensor Hardware Devices to either GPU or CPU
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# Calls the model.forward() function to generate predictions
predictions = model(images)我们将这批图像直接传递给模型,该模型将由模型中定义的前向函数处理。一旦我们有了预测,我们就可以优化我们的模型权重。
优化代码如下所示:
# Calculate Cross Entropy Loss
loss = criterion(predictions, labels)
# Clears gradient values from previous batch
optimizer.zero_grad()
# Computes backprop gradient based on the loss
loss.backward()
# Optimizes the model weights
optimizer.step()使用上面的代码,我们可以计算所有的反向传播梯度,并使用 Adam 优化器优化模型权重。上述所有代码组合在一起可以训练我们的模型趋同。
完整的训练循环如下所示:
for epoch in range(NUM_EPOCHS):
total_epoch_loss = 0
steps = 0
for batch in iter(train_dataloader):
images, labels = batch # Separate inputs and labels
# Convert Tensor Hardware Devices to either GPU or CPU
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# Calls the model.forward() function to generate predictions
predictions = model(images)
# Calculate Cross Entropy Loss
loss = criterion(predictions, labels)
# Clears gradient values from previous batch
optimizer.zero_grad()
# Computes backprop gradient based on the loss
loss.backward()
# Optimizes the model weights
optimizer.step()
steps += 1
total_epoch_loss += loss.item()
print(f'Epoch: {epoch + 1} / {NUM_EPOCHS}: Average Loss: {total_epoch_loss / steps}')损失逐渐减少并接近0。然后,我们可以在最初声明的测试数据集上评估模型。
评估我们的模型性能
for batch in iter(test_dataloader):
images, labels = batch
images = images.to(DEVICE)
labels = labels.to(DEVICE)
predictions = model(images)
# Taking the predicted label with highest probability
predictions = torch.argmax(predictions, dim=1)
correct_predictions += (predictions == labels).sum().item()
total_predictions += labels.shape[0]
print(f"\nTEST ACCURACY: {((correct_predictions / total_predictions) * 100):.2f}")与训练循环类似,我们迭代测试数据集中的每个批次进行评估。我们为输入生成预测。但是,对于评估,我们只需要概率最高的标签。argmax 函数提供此功能来获取预测数组中具有最高值的值的索引。
对于准确率分数,我们可以比较预测的标签是否与真实的目标标签匹配。然后,我们计算正确标签数除以预测标签总数的准确性。
结果
我只训练了五个时期的模型,测试准确率超过96%,而训练前的准确率为10%。下图显示了训练五个 epoch 后的模型预测。
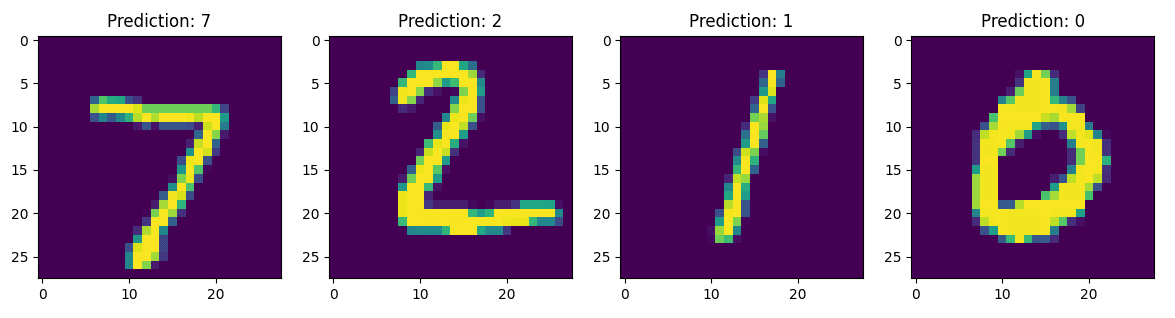
你有它。您现在已经从头开始实现了一个模型,该模型可以仅区分手写数字和图像像素值。
这绝不是 PyTorch 的全面指南,但它确实为您提供了对机器学习项目中的结构和数据流的一般了解。尽管如此,这些知识足以让您开始在深度学习中实现最先进的架构。
完整代码
完整代码如下:
model.py:
import torch
import torch.nn as nn
class Classifier(nn.Module):
def __init__(
self,
input_size:int,
num_classes:int
) -> None:
super().__init__()
self.input_layer = nn.Linear(input_size, 512)
self.hidden_1 = nn.Linear(512, 256)
self.hidden_2 = nn.Linear(256, 128)
self.output_layer = nn.Linear(128, num_classes)
self.activation = nn.ReLU()
def forward(self, x):
# Pass Input Sequentially through each dense layer and activation
x = self.activation(self.input_layer(x))
x = self.activation(self.hidden_1(x))
x = self.activation(self.hidden_2(x))
return self.output_layer(x)main.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
# Using MNIST dataset provided by PyTorch
from torchvision.datasets.mnist import MNIST
import torchvision.transforms as transforms
# Import Model implemented in a different file
from model import Classifier
import matplotlib.pyplot as plt
if __name__ == "__main__":
INPUT_SIZE = 784 # Flattened 28x28 images
NUM_CLASSES = 10 # 0-9 hand-written digits.
BATCH_SIZE = 128 # Using Mini-Batches for Training
LEARNING_RATE = 0.01 # Opitimizer Step
NUM_EPOCHS = 5 # Total Training Epochs
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
# Will be used to convert Images to PyTorch Tensors
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: torch.flatten(x))
])
train_dataset = MNIST(root=".data/", train=True, download=True, transform=data_transforms)
test_dataset = MNIST(root=".data/", train=False, download=True, transform=data_transforms)
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
model = Classifier(input_size=784, num_classes=10)
model.to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
for epoch in range(NUM_EPOCHS):
total_epoch_loss = 0
steps = 0
for batch in iter(train_dataloader):
images, labels = batch # Separate inputs and labels
# Convert Tensor Hardware Devices to either GPU or CPU
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# Calls the model.forward() function to generate predictions
predictions = model(images)
# Calculate Cross Entropy Loss
loss = criterion(predictions, labels)
# Clears gradient values from previous batch
optimizer.zero_grad()
# Computes backprop gradient based on the loss
loss.backward()
# Optimizes the model weights
optimizer.step()
steps += 1
total_epoch_loss += loss.item()
print(f'Epoch: {epoch + 1} / {NUM_EPOCHS}: Average Loss: {total_epoch_loss / steps}')
# Save Trained Model
torch.save(model.state_dict(), 'trained_model.pth')
model.eval()
correct_predictions = 0
total_predictions = 0
for batch in iter(test_dataloader):
images, labels = batch
images = images.to(DEVICE)
labels = labels.to(DEVICE)
predictions = model(images)
# Taking the predicted label with highest probability
predictions = torch.argmax(predictions, dim=1)
correct_predictions += (predictions == labels).sum().item()
total_predictions += labels.shape[0]
print(f"\nTEST ACCURACY: {((correct_predictions / total_predictions) * 100):.2f}")
# -- Code For Plotting Results -- #
batch = next(iter(test_dataloader))
images, labels = batch
fig, ax = plt.subplots(nrows=1, ncols=4, figsize=(16,8))
for i in range(4):
image = images[i]
prediction = torch.softmax(model(image), dim=0)
prediction = torch.argmax(prediction, dim=0)
# print(type(prediction), type(prediction.item()))
ax[i].imshow(image.view(28,28))
ax[i].set_title(f'Prediction: {prediction.item()}')
plt.show()由3D建模学习工作室 整理翻译,转载请注明出处!