在 PyTorch 中构建卷积神经网络
神经网络由相互连接的层构建而成。有许多不同类型的层。对于与图像相关的应用程序,您始终可以找到卷积层。它是一个参数很少的层,但应用于大尺寸输入。它之所以强大,是因为它可以保留图像的空间结构。因此,它被用于在计算机视觉神经网络上产生最先进的结果。在这篇文章中,您将了解卷积层及其构建的网络。
推荐:将NSDT场景编辑器加入你的3D工具链
3D工具集:NSDT简石数字孪生
在 PyTorch 中构建卷积神经网络
完成这篇文章后,您将知道:
- 什么是卷积层和池化层
- 它们如何在神经网络中组合在一起
- 如何使用卷积层的神经网络

概述
这篇文章分为四个部分;他们是
- 卷积神经网络的案例
- 卷积神经网络的构建块
- 卷积神经网络示例
- 特征图中有什么?
卷积神经网络的案例
让我们考虑制作一个神经网络来处理灰度图像作为输入,这是计算机视觉深度学习中最简单的用例。
灰度图像是一个像素数组。每个像素通常是一个介于 0 到 255 之间的值。大小为 32×32 的图像将具有 1024 像素。将其作为神经网络的输入意味着第一层至少有 1024 个输入权重。
查看像素值对理解图片几乎没有用处,因为数据隐藏在空间结构中(例如,图片上是否有水平线或垂直线)。因此,传统的神经网络将发现很难从图像输入中找出信息。
卷积神经网络是利用卷积层来保留像素的空间信息。它了解相邻像素的相似程度并生成特征表示。卷积层从图片中看到的东西在某种程度上与失真是不变的。例如,卷积神经网络可以预测相同的结果,即使输入图像的颜色发生了变化、旋转或重新缩放。此外,卷积层的权重较小,因此更容易训练。
卷积神经网络的构建块
卷积神经网络最简单的用例是分类。您会发现它包含三种类型的图层:
- 卷积层
- 池化层
- 全连接层
卷积层上的神经元称为过滤器。通常它是图像应用中的二维卷积层。过滤器是应用于输入图像像素的 2D 补丁(例如,2×3 像素)。这个3D贴片的大小也称为感受野,这意味着它一次可以看到图像的多大部分。
卷积层的滤波器是与输入像素相乘,然后求和结果。此结果是输出处的一个像素值。过滤器将在输入图像周围移动以填充输出中的所有像素值。通常将多个过滤器应用于同一输入,从而产生多个输出张量。这些输出张量称为该层生成的特征图。它们作为一个张量堆叠在一起,并作为输入传递到下一层。
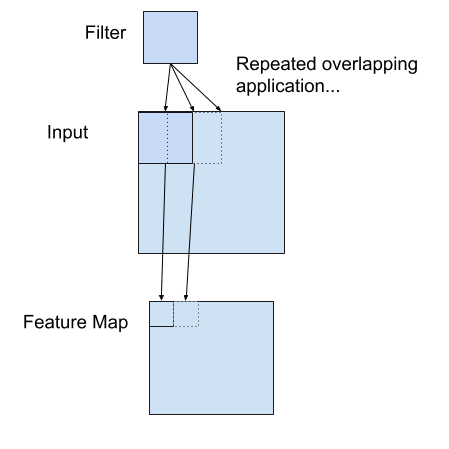
应用于二维输入以创建特征映射的筛选器示例
卷积层的输出称为特征图,因为它通常了解输入图像的特征。例如,位置是否有垂直线。从像素中学习特征有助于在更高层次上理解图像。多个卷积层堆叠在一起,以便从较低级别的细节推断出更高级别的特征。
池化层是对前一层的特征图进行下采样。它通常在卷积层之后使用,以巩固学习的特征。它可以压缩和概化特征表示。池化层也有一个感受野,通常是取感受野上所有值的平均值(平均池化)或最大值(最大池化)。
全连接层通常是网络中的最后一层。它是将先前的卷积层和池化层合并的特征作为输入来生成预测。可能有多个完全连接的层堆叠在一起。在分类的情况下,您通常会看到最终全连接层的输出与 softmax 函数一起应用以生成类似概率的分类。
想开始使用 PyTorch 进行深度学习吗?
立即参加我的免费电子邮件速成课程(带有示例代码)。
单击以注册并获得该课程的免费PDF电子书版本。
下载您的免费迷你课程
卷积神经网络示例
以下是对 CIFAR-10 数据集进行图像分类的程序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | import torch import torch.nn as nn import torch.optim as optim import torchvision transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()]) trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) batch_size = 32 trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True) testloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True) class CIFAR10Model(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=(3,3), stride=1, padding=1) self.act1 = nn.ReLU() self.drop1 = nn.Dropout(0.3) self.conv2 = nn.Conv2d(32, 32, kernel_size=(3,3), stride=1, padding=1) self.act2 = nn.ReLU() self.pool2 = nn.MaxPool2d(kernel_size=(2, 2)) self.flat = nn.Flatten() self.fc3 = nn.Linear(8192, 512) self.act3 = nn.ReLU() self.drop3 = nn.Dropout(0.5) self.fc4 = nn.Linear(512, 10) def forward(self, x): # input 3x32x32, output 32x32x32 x = self.act1(self.conv1(x)) x = self.drop1(x) # input 32x32x32, output 32x32x32 x = self.act2(self.conv2(x)) # input 32x32x32, output 32x16x16 x = self.pool2(x) # input 32x16x16, output 8192 x = self.flat(x) # input 8192, output 512 x = self.act3(self.fc3(x)) x = self.drop3(x) # input 512, output 10 x = self.fc4(x) return x model = CIFAR10Model() loss_fn = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) n_epochs = 20 for epoch in range(n_epochs): for inputs, labels in trainloader: # forward, backward, and then weight update y_pred = model(inputs) loss = loss_fn(y_pred, labels) optimizer.zero_grad() loss.backward() optimizer.step() acc = 0 count = 0 for inputs, labels in testloader: y_pred = model(inputs) acc += (torch.argmax(y_pred, 1) == labels).float().sum() count += len(labels) acc /= count print("Epoch %d: model accuracy %.2f%%" % (epoch, acc*100)) torch.save(model.state_dict(), "cifar10model.pth") |
CIFAR-10 数据集提供 32×32 像素的 RGB 颜色图像(即 3 个颜色通道)。有 10 个类,以整数 0 到 9 标记。每当您使用图像的 PyTorch 神经网络模型时,您都会发现姊妹库很有用。在上面,你用它从互联网上下载了 CIFAR-10 数据集,并将其转换为 PyTorch 张量:torchvision
1 2 3 4 5 | ... transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()]) trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) |
您还使用了 PyTorch 中的 来帮助创建用于训练的批处理。训练是使用随机梯度下降来优化模型的交叉熵损失。它是一个分类模型,因此分类的准确性比交叉熵更直观,交叉熵是在每个纪元结束时计算的,通过将输出 logit 中的最大值与数据集的标签进行比较:DataLoader
1 2 | ... acc += (torch.argmax(y_pred, 1) == labels).float().sum() |
运行上面的程序来训练网络需要时间。该网络应该能够在分类中达到70%以上的准确率。
在网络中,图像分类通常在早期阶段由卷积层组成,辍学层和池化层交错。然后,在稍后阶段,卷积层的输出被展平并由一些全连接层处理。
特征图中有什么?
上面定义的网络中有两个卷积层。它们都定义为内核大小为 3×3,因此它一次查看 9 个像素以生成一个输出像素。请注意,第一个卷积层将RGB图像作为输入。因此,每个像素都有三个通道。第二个卷积层采用具有 32 个通道的特征图作为输入。它看到的每个“像素”将有 32 个值。因此,第二卷积层具有更多的参数,即使它们具有相同的感受野。
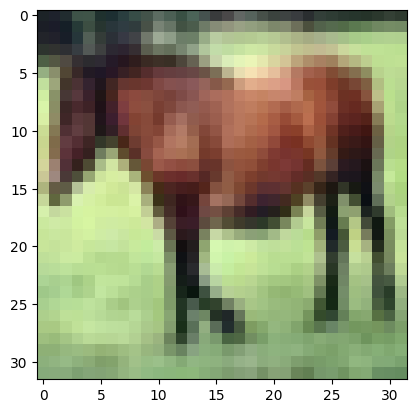
让我们看看特征图中有什么。假设我们从训练集中选择一个输入样本:
1 2 3 4 | import matplotlib.pyplot as plt plt.imshow(trainset.data[7]) plt.show() |
您应该看到这是一匹马的图像,32×32像素,带有RGB通道:
首先,您需要将其转换为 PyTorch 张量,并使其成为一个图像的批处理。PyTorch 模型期望每个图像作为(通道、高度、宽度)格式的张量,但您读取的数据采用 (高度、宽度、通道) 格式。如果您用于将图像转换为 PyTorch 张量,则此格式转换会自动完成。否则,您需要在使用前排列尺寸。torchvision
之后,将其传递到模型的第一个卷积层并捕获输出。你需要告诉 PyTorch 这个计算不需要梯度,因为你不打算优化模型权重:
1 2 3 4 | X = torch.tensor([trainset.data[7]], dtype=torch.float32).permute(0,3,1,2) model.eval() with torch.no_grad(): feature_maps = model.conv1(X) |
特征图在一个张量中。您可以使用 matplotlib 可视化它们:
1 2 3 4 5 | fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8)) for i in range(0, 32): row, col = i//8, i%8 ax[row][col].imshow(feature_maps[0][i]) plt.show() |
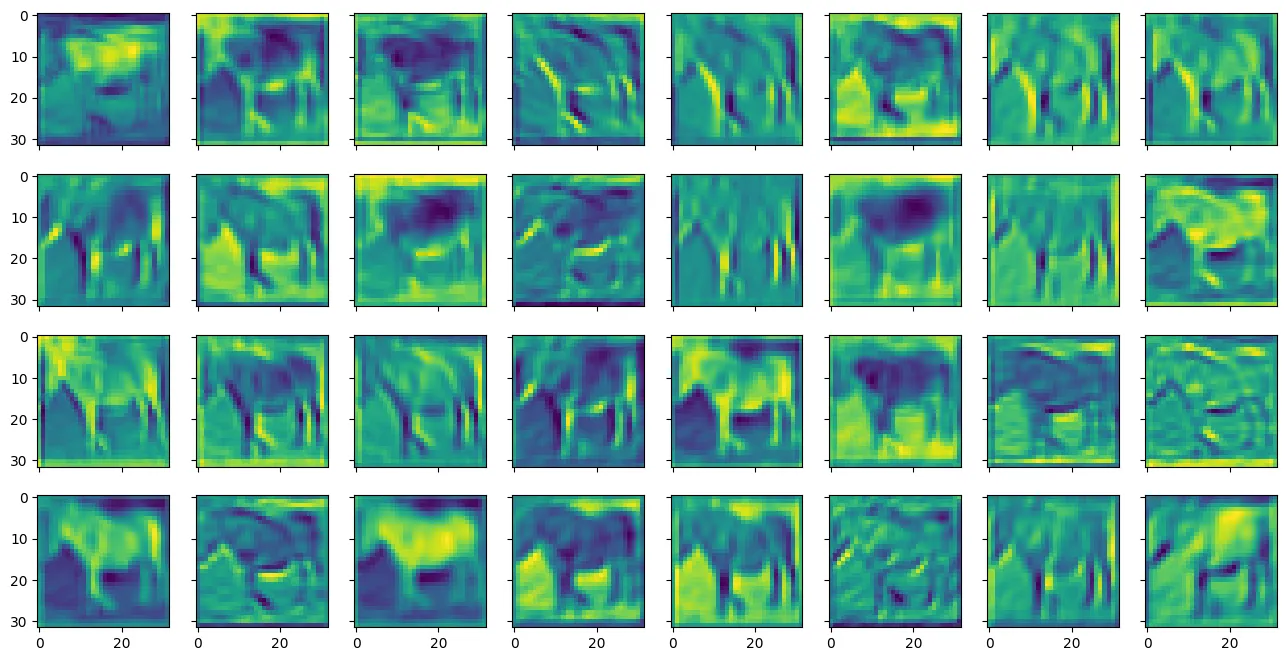
您可能会看到以下内容:
您可以看到它们被称为特征图,因为它们突出显示了输入图像中的某些特征。使用小窗口(在本例中为 3×3 像素过滤器)标识要素。输入图像有三个颜色通道。每个通道都应用了不同的滤波器,并且它们的结果将合并为输出要素。
类似地,您可以从第二个卷积层的输出中显示特征图,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 | X = torch.tensor([trainset.data[7]], dtype=torch.float32).permute(0,3,1,2) model.eval() with torch.no_grad(): feature_maps = model.act1(model.conv1(X)) feature_maps = model.drop1(feature_maps) feature_maps = model.conv2(feature_maps) fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8)) for i in range(0, 32): row, col = i//8, i%8 ax[row][col].imshow(feature_maps[0][i]) plt.show() |
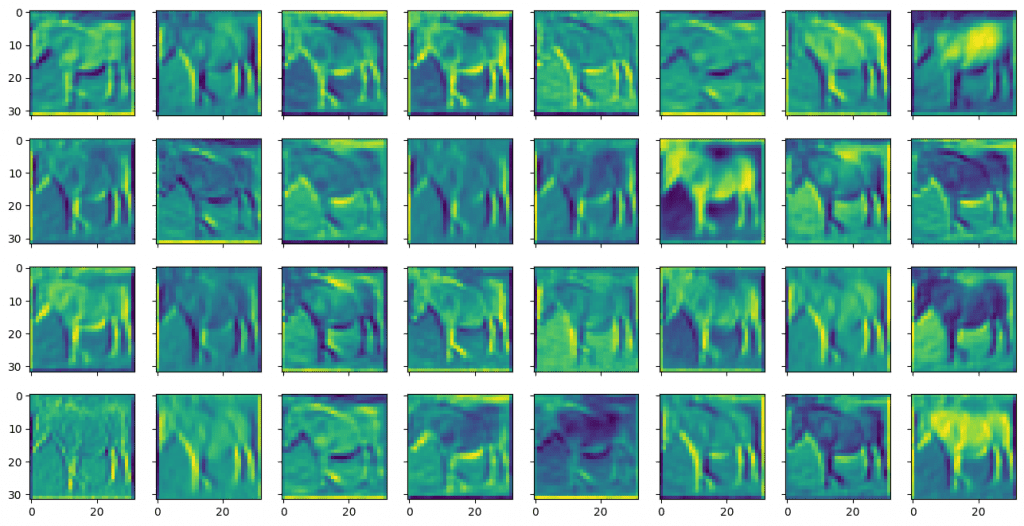
其中显示:
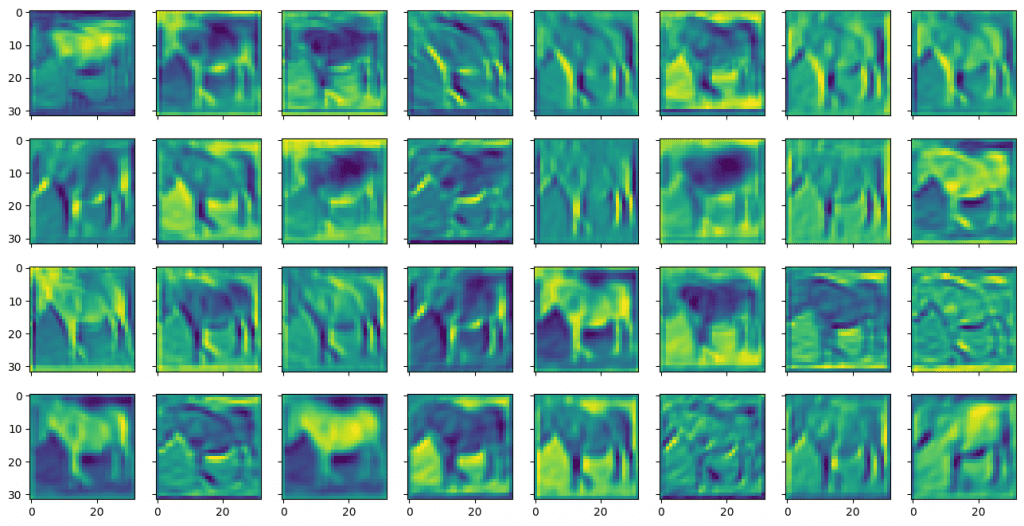
与第一卷积层的输出相比,来自第二卷积层的特征图看起来更模糊且更抽象。但这些对于模型识别对象更有用。
将所有内容放在一起,下面的代码加载上一节中保存的模型并生成特征图:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | import torch import torch.nn as nn import torchvision import matplotlib.pyplot as plt trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True) class CIFAR10Model(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=(3,3), stride=1, padding=1) self.act1 = nn.ReLU() self.drop1 = nn.Dropout(0.3) self.conv2 = nn.Conv2d(32, 32, kernel_size=(3,3), stride=1, padding=1) self.act2 = nn.ReLU() self.pool2 = nn.MaxPool2d(kernel_size=(2, 2)) self.flat = nn.Flatten() self.fc3 = nn.Linear(8192, 512) self.act3 = nn.ReLU() self.drop3 = nn.Dropout(0.5) self.fc4 = nn.Linear(512, 10) def forward(self, x): # input 3x32x32, output 32x32x32 x = self.act1(self.conv1(x)) x = self.drop1(x) # input 32x32x32, output 32x32x32 x = self.act2(self.conv2(x)) # input 32x32x32, output 32x16x16 x = self.pool2(x) # input 32x16x16, output 8192 x = self.flat(x) # input 8192, output 512 x = self.act3(self.fc3(x)) x = self.drop3(x) # input 512, output 10 x = self.fc4(x) return x model = CIFAR10Model() model.load_state_dict(torch.load("cifar10model.pth")) plt.imshow(trainset.data[7]) plt.show() X = torch.tensor([trainset.data[7]], dtype=torch.float32).permute(0,3,1,2) model.eval() with torch.no_grad(): feature_maps = model.conv1(X) fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8)) for i in range(0, 32): row, col = i//8, i%8 ax[row][col].imshow(feature_maps[0][i]) plt.show() with torch.no_grad(): feature_maps = model.act1(model.conv1(X)) feature_maps = model.drop1(feature_maps) feature_maps = model.conv2(feature_maps) fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8)) for i in range(0, 32): row, col = i//8, i%8 ax[row][col].imshow(feature_maps[0][i]) plt.show() |
3D建模学习工作室 翻译整理,转载请注明出处!