使用强化学习训练扩散模型
在产生复杂的高维输出时,扩散模型很难被击败。然而,到目前为止,它们大多在目标是从大量数据(例如,图像-标题对)中学习模式的应用程序中取得了成功。我们发现了一种超越模式匹配的方式有效地训练扩散模型的方法,而且不一定需要任何训练数据。可能性仅受奖励函数的质量和创造力的限制。

在线工具推荐:三维数字孪生场景工具 - GLTF/GLB在线编辑器 - Three.js AI自动纹理化开发 - YOLO 虚幻合成数据生成器 - 3D模型在线转换
扩散模型最近已成为生成复杂、高维输出的事实标准。您可能知道他们能够制作令人惊叹的 AI 艺术和超逼真的合成图像,但他们在其他应用中也取得了成功,例如药物设计和连续控制。扩散模型背后的关键思想是迭代地将随机噪声转换为样本,例如图像或蛋白质结构。这通常被激励为最大似然估计问题,其中模型被训练以生成尽可能接近训练数据的样本。
然而,扩散模型的大多数用例并不直接涉及匹配训练数据,而是与下游目标有关。我们不仅想要一个看起来像现有图像的图像,而且想要一个具有特定类型外观的图像;我们不仅想要一种物理上合理的药物分子,而且想要一种尽可能有效的药物分子。在这篇文章中,我们展示了如何使用强化学习 (RL) 直接在这些下游目标上训练扩散模型。为此,我们在各种目标上微调了稳定扩散,包括图像可压缩性、人类感知的美学质量和快速图像对齐。最后一个目标使用来自大型视觉语言模型的反馈来提高模型在异常提示下的性能,展示了如何在没有任何人类参与的情况下使用强大的 AI 模型来相互改进。
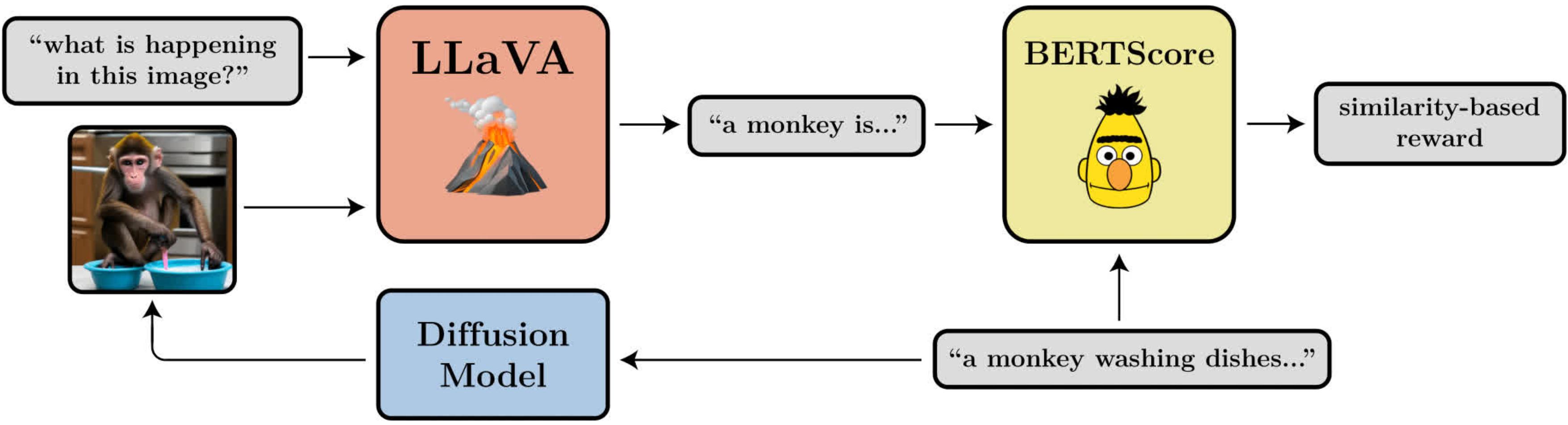
说明提示图像对齐目标的图表。它使用大型视觉语言模型 LLaVA 来评估生成的图像。
去噪扩散策略优化
当将扩散转化为RL问题时,我们只做出最基本的假设:给定一个样本(例如图像),我们可以访问一个奖励函数,我们可以评估该函数以告诉我们该样本的“好”程度。我们的目标是让扩散模型生成最大化此奖励函数的样本。
扩散模型通常使用源自最大似然估计 (MLE) 的损失函数进行训练,这意味着鼓励它们生成使训练数据看起来更有可能的样本。在RL设置中,我们不再有训练数据,只有来自扩散模型的样本及其相关的奖励。我们仍然可以使用相同的 MLE 激励损失函数的一种方法是将样本视为训练数据,并通过将每个样本的损失加权与其奖励来合并奖励。这为我们提供了一种算法,我们称之为奖励加权回归 (RWR),这是在 RL 文献中的现有算法之后。
但是,这种方法存在一些问题。一是RWR不是一个特别精确的算法——它只使奖励最大化(参见Nair等人,附录A)。MLE激发的扩散损失也不精确,而是使用每个样本的真实似然的变分界得出的。这意味着 RWR 通过两个近似级别来最大化奖励,我们发现这严重损害了其性能。
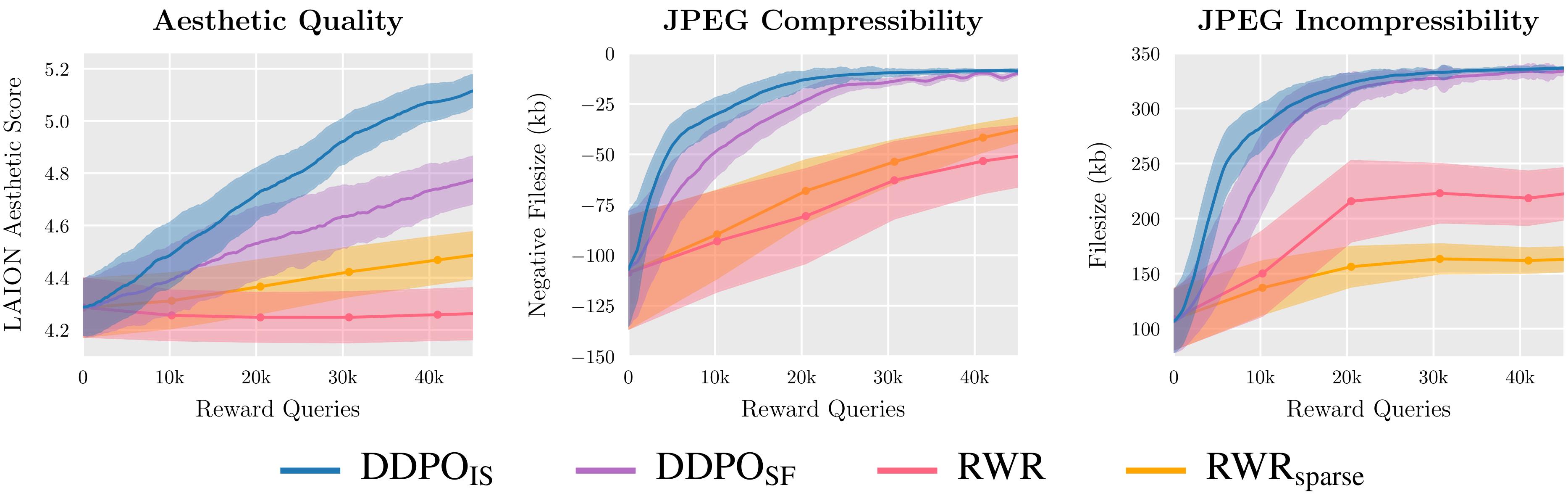
我们在三个奖励函数上评估了 DDPO 的两种变体和 RWR 的两种变体,发现 DDPO 始终实现最佳性能。
我们的算法(我们称之为去噪扩散策略优化 (DDPO))的关键见解是,如果我们关注使我们到达那里的整个去噪步骤序列,我们可以更好地最大化最终样本的奖励。为此,我们将扩散过程重新构建为多步骤马尔可夫决策过程(MDP)。用 MDP 术语来说:每个去噪步骤都是一个动作,当产生最终样本时,智能体只有在每个去噪轨迹的最后一步才能获得奖励。该框架允许我们应用RL文献中的许多强大算法,这些算法是专门为多步MDP设计的。这些算法不使用最终样本的近似似然,而是使用每个去噪步骤的确切似然,这非常容易计算。
我们之所以选择应用策略梯度算法,是因为它们易于实现,并且过去在语言模型微调方面取得了成功。这导致了 DDPO 的两种变体:DDPO SF,它使用策略梯度的简单得分函数估计器,也称为 REINFORCE;以及 DDPOIS,它使用更强大的重要性采样估计器。DDPOIS是我们性能最好的算法,其实现与近端策略优化(PPO)的实现密切相关。
使用 DDPO 微调稳定扩散
对于我们的主要结果,我们使用 DDPOIS 微调 Stable Diffusion v1-4。我们有四个任务,每个任务由不同的奖励函数定义:
- 可压缩性:使用 JPEG 算法压缩图像的难易程度如何?奖励是保存为 JPEG 时图像的负文件大小(以 kB 为单位)。
- 不可压缩性:使用 JPEG 算法压缩图像的难度有多大?奖励是保存为 JPEG 时图像的正文件大小(以 kB 为单位)。
- 审美质量:图像对人眼的美感如何?奖励是LAION美学预测器的输出,这是一个根据人类偏好训练的神经网络。
- 提示图像对齐:图像在多大程度上代表了提示中要求的内容?这个有点复杂:我们将图像输入LLaVA,要求它描述图像,然后使用BERTScore计算该描述与原始提示之间的相似性。
由于 Stable Diffusion 是一个文本到图像的模型,我们还需要选择一组提示来在微调时给出它。对于前三个任务,我们使用“a(n) [animal]”形式的简单提示。对于提示图像对齐,我们使用“a(n) [动物] [活动]”形式的提示,其中活动是“洗碗”、“下棋”和“骑自行车”。我们发现,在这些不寻常的场景中,Stable Diffusion 通常难以生成与提示相匹配的图像,因此 RL 微调还有很大的改进空间。
首先,我们说明了 DDPO 在简单奖励(可压缩性、不可压缩性和美学质量)上的表现。所有图像都是使用相同的随机种子生成的。在左上象限中,我们说明了 Stable Diffusion 为九种不同动物产生的“香草”;所有RL微调模型都显示出明显的质的差异。有趣的是,审美质量模型(右上)倾向于极简主义的黑白线条图,揭示了LAION审美预测器认为“更具审美性”的图像类型。

接下来,我们在更复杂的提示图像对齐任务中演示 DDPO。在这里,我们展示了训练过程中的几个快照:每个系列的三张图像显示了随时间推移的相同提示和随机种子的样本,第一个样本来自香草稳定扩散。有趣的是,该模型转向更卡通的风格,这不是故意的。我们假设这是因为进行类似人类活动的动物更有可能在预训练数据中以卡通风格出现,因此模型转向这种风格,以便通过利用它已经知道的内容更容易与提示保持一致。

意外泛化
当使用RL微调大型语言模型时,已经发现出现了令人惊讶的泛化:例如,仅用英语微调指令遵循的模型通常会在其他语言中得到改进。我们发现,文本到图像扩散模型也会出现同样的现象。例如,我们的审美质量模型使用从 45 种常见动物列表中选择的提示进行了微调。我们发现它不仅适用于看不见的动物,还适用于日常物品。

我们的提示图像对齐模型在训练期间使用了相同的 45 只常见动物列表,并且只使用了 <> 项活动。我们发现它不仅适用于看不见的动物,还推广到看不见的活动,甚至是两者的新组合。

过度优化
众所周知,对奖励函数(尤其是学习函数)进行微调会导致奖励过度优化,其中模型利用奖励函数以无用的方式获得高奖励。我们的设置也不例外:在所有任务中,模型最终会破坏任何有意义的图像内容,以最大化奖励。

我们还发现 LLaVA 容易受到排版攻击:当优化与“[n] animals”形式的提示对齐时,DDPO 能够通过生成松散地类似于正确数字的文本来成功欺骗 LLaVA。

目前还没有防止过度优化的通用方法,我们强调这个问题是未来工作的一个重要领域。
结论
在产生复杂的高维输出时,扩散模型很难被击败。然而,到目前为止,它们大多在目标是从大量数据(例如,图像-标题对)中学习模式的应用程序中取得了成功。我们发现了一种超越模式匹配的方式有效地训练扩散模型的方法,而且不一定需要任何训练数据。可能性仅受奖励函数的质量和创造力的限制。
我们在这项工作中使用 DDPO 的方式受到语言模型微调最近成功案例的启发。OpenAI 的 GPT 模型,如 Stable Diffusion,首先在大量互联网数据上进行训练;然后使用 RL 对它们进行微调,以生成有用的工具,例如 ChatGPT。通常,它们的奖励函数是从人类的偏好中学习的,但其他人最近已经弄清楚了如何使用基于人工智能反馈的奖励函数来生成强大的聊天机器人。与聊天机器人制度相比,我们的实验规模小,范围有限。但考虑到这种“预训练+微调”范式在语言建模中的巨大成功,在扩散模型领域似乎值得进一步追求。我们希望其他人可以在我们的工作基础上改进大型扩散模型,不仅用于文本到图像的生成,还用于许多令人兴奋的应用,如视频生成、音乐生成、图像编辑、蛋白质合成、机器人技术等。
此外,“预训练+微调”范式并不是使用 DDPO 的唯一方法。只要你有一个好的奖励函数,就没有什么能阻止你从一开始就用RL进行训练。虽然这种设置尚未被探索,但这是 DDPO 的优势可以真正发挥作用的地方。长期以来,纯RL一直被应用于各种领域,从玩游戏到机器人操作,从核聚变到芯片设计。将扩散模型的强大表现力添加到组合中,有可能将RL的现有应用提升到一个新的水平,甚至发现新的应用。