使用生成式 AI 模仿人类行为
使用生成式 AI 模仿人类行为
推荐:使用NSDT场景编辑器助你快速搭建可编辑的3D应用场景
这项研究被 2023 年学习表征国际会议 (ICLR) 接受,该会议致力于推进通常称为深度学习的人工智能分支。
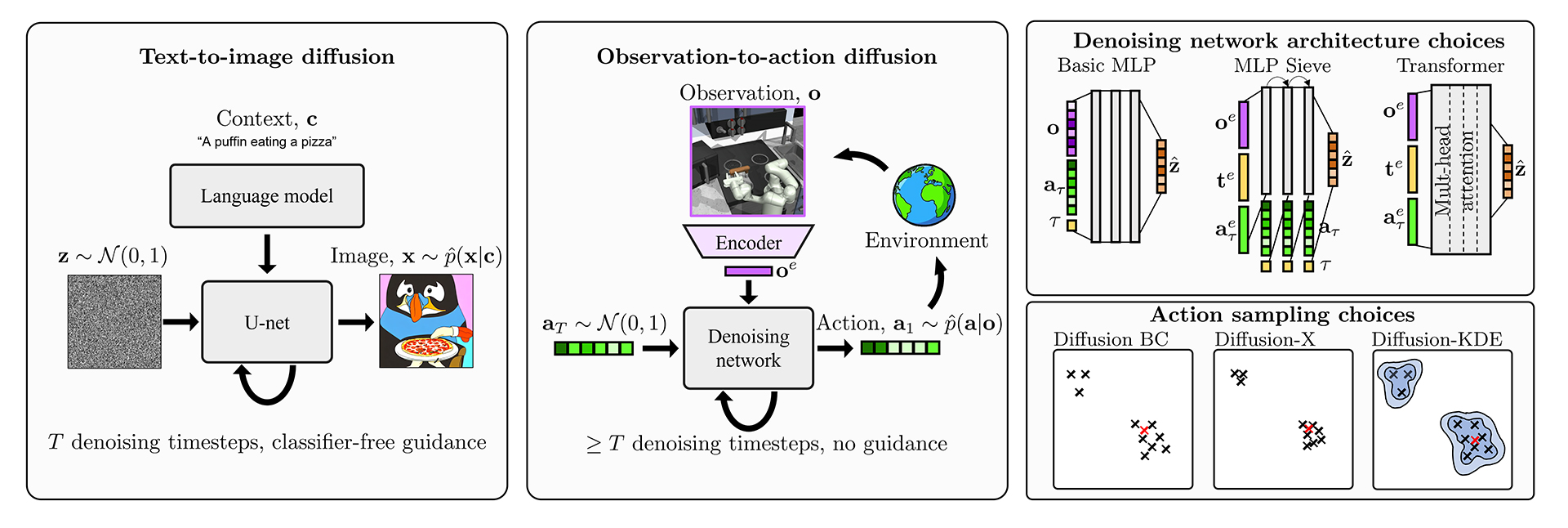
扩散模型已成为一类强大的生成式AI模型。它们已被用于生成逼真的图像和短视频、创作音乐和合成语音。它们的用途并不止于此。在我们的新论文《用扩散模型模仿人类行为》中,我们探讨了如何使用它们在交互式环境中模仿人类行为。
此功能在许多应用程序中都很有价值。例如,它可以帮助自动化机器人中的重复操作任务,或者可以用来在视频游戏中创建类似人类的人工智能,这可能会带来令人兴奋的新游戏体验——这是我们团队特别重视的目标。
我们遵循一种称为模仿学习(更具体地说是行为克隆)的机器学习范式。在这种范式中,我们得到了一个数据集,其中包含一个人在环境中行动时看到的观察结果,以及他们采取的行动,我们希望AI代理能够模仿这些观察结果。在交互式环境中,在每个时间步长,观察结果��收到(例如视频游戏的屏幕截图)和操作一个�然后选择(例如鼠标移动)。有了这个许多数据集�的和一个由某个演示者执行的模型�可以尝试学习这种观察到行动的映射,�(�)→一个.

当操作是连续的时,训练模型来学习此映射会带来一些有趣的挑战。特别是,应该使用什么损失函数?一个简单的选择是均方误差,这通常用于监督回归任务。在交互式环境中,此目标鼓励代理学习数据集中所有行为的平均值。
如果应用程序的目标是生成不同的人类行为,则平均值可能不是很有用。毕竟,人类是随机的(他们心血来潮)和多模态生物(不同的人可能会做出不同的决定)。图2描述了多模态时均方误差无法模拟真实动作分布(以黄色标记)的情况。它还包括进行行为克隆时损失函数的其他几种流行选择。

理想情况下,我们希望我们的模型能够学习各种人类行为。这就是生成模型提供帮助的地方。扩散模型是一类特定的生成模型,既可以稳定训练,又易于采样。他们在文本到图像领域非常成功,该领域面临着一对多的挑战——单个文本标题可能与多个不同的图像相匹配。
我们的工作将文本到图像扩散模型开发的想法适应了这种观察到行动扩散的新范式。图 1 突出显示了一些差异。一个明显的点是,我们正在生成的对象现在是一个低维动作向量(而不是图像)。这就需要对降噪网络架构进行新的设计。在图像生成中,重型卷积U-Net很流行,但这些不太适用于低维向量。相反,我们创新和测试了图 1 所示的三种不同的架构。
在观察到行动模型中,在发作期间对单个不良动作进行采样可能会使代理偏离正轨,因此我们有动力开发采样方案,以更可靠地返回良好的行动样本(也如图 1 所示)。在文本到图像模型中,这个问题不太严重,因为用户通常可以从多个生成的样本中选择单个图像并忽略任何不良图像。图 3 显示了一个示例,其中用户可能会挑选他们最喜欢的内容,而忽略带有无意义文本的那个。
我们在两种不同的环境中测试了我们的扩散剂。第一个是模拟厨房环境,这是一个具有挑战性的高维连续控制问题,其中机械臂必须操纵各种物体。演示数据集是从以不同顺序执行各种任务的各种人类那里收集的。因此,数据集中存在丰富的多模态。
我们发现扩散剂在两个方面优于基线。1)他们学习的行为多样性更广泛,更接近人类示范。2)任务完成率(奖励的代理)更好。
下面的视频重点介绍了扩散捕获多模态行为的能力——从相同的初始条件开始,我们推出了扩散剂八次。每次它都会选择要完成的不同任务序列。
测试的第二个环境是现代3D视频游戏Counter-Strike。我们向感兴趣的读者推荐该论文以获取结果。
总之,我们的工作已经证明了如何利用生成建模的最新进展来构建可以在交互式环境中以类似人类的方式行事的代理。我们很高兴能继续探索这个方向——关注这个空间的未来工作。
由3D建模学习工作室 整理翻译,转载请注明出处!