了解机器学习算法:深入概述
机器学习。相当令人印象深刻的词块,对吗?由于人工智能及其工具,如ChatGPT和Bard,现在蓬勃发展,是时候更深入地学习基础知识了。

推荐:使用NSDT编辑器快速搭建3D应用场景
这些基本概念可能不会立即启发您,但是如果您对这些概念感兴趣,您将有进一步的链接来更深入。
机器学习的优势来自于其复杂的算法,这是每个机器学习项目的核心。有时,这些算法甚至从人类认知中汲取灵感,如语音识别或面部识别。
在本文中,我们将首先解释机器学习类,例如有监督、无监督和强化学习。
然后,我们将进入机器学习处理的任务,名称是分类、回归和聚类。
之后,我们将深入发现决策树、支持向量机和 k 最近邻以及线性回归、视觉和定义。
但是,当然,您如何选择符合您需求的最佳算法?当然,理解“理解数据”或“定义问题”等概念将指导您解决项目中可能的挑战和障碍。
让我们开始机器学习之旅吧!
机器学习的类别
当我们探索机器学习时,我们可以看到有三个主要类别塑造了它的框架。
- 监督学习
- 无监督学习
- 强化学习。
在监督学习中,要预测的标签位于数据集中。
在这种情况下,算法就像一个细心的学习者,将特征与相应的输出相关联。学习阶段结束后,它可以投影新数据的输出,并测试数据。考虑标记垃圾邮件或预测房价等方案。
想象一下接下来没有导师的学习;这一定令人望而生畏。无监督学习方法尤其这样做,在没有标签的情况下进行预测。
他们勇敢地进入未知领域,在未标记的数据中发现隐藏的模式和结构,类似于探索者发现丢失的文物。
了解生物学中的遗传结构和营销中的客户细分是无监督学习的例子。
最后,我们到达强化学习,算法通过犯错误来学习,就像小狗一样。想象一下教宠物:不鼓励不当行为,而良好的行为会得到奖励。
与此类似,该算法采取行动,体验奖励或惩罚,并最终弄清楚如何优化。这种策略经常用于机器人和视频游戏等行业。
机器学习的类型
在这里,我们将机器算法分为三个小节。这些子部分是分类、回归和聚类。
分类
顾名思义,分类侧重于对项目进行分组或分类的过程。把自己想象成一个植物学家,负责根据各种特征将植物分类为良性或危险类别。这类似于根据糖果的颜色将糖果分类到不同的罐子中。
回归
回归是下一步;可以将其视为预测数值变量的尝试。
在这种情况下,目标是预测某个变量,例如考虑其特征(房间数量、位置等)的房产成本。
这类似于使用水果的尺寸计算出水果的大量数量,因为没有明确定义的类别,而是一个连续的范围。
聚类
我们现在到达聚类,这相当于组织杂乱无章的衣服。即使您缺少预设类别(或标签),您仍然可以将相关对象放在一起。
想象一下,有一种算法,在没有事先了解所涉及的主题的情况下,根据这些主题对新闻报道进行分类。那里的聚类很明显!
让我们分析一些完成这些工作的流行算法,因为还有很多东西需要探索!
流行的机器学习算法
在这里,我们将更深入地介绍流行的机器学习算法,如决策树、支持向量机、K 近邻和线性回归。
A. 决策树
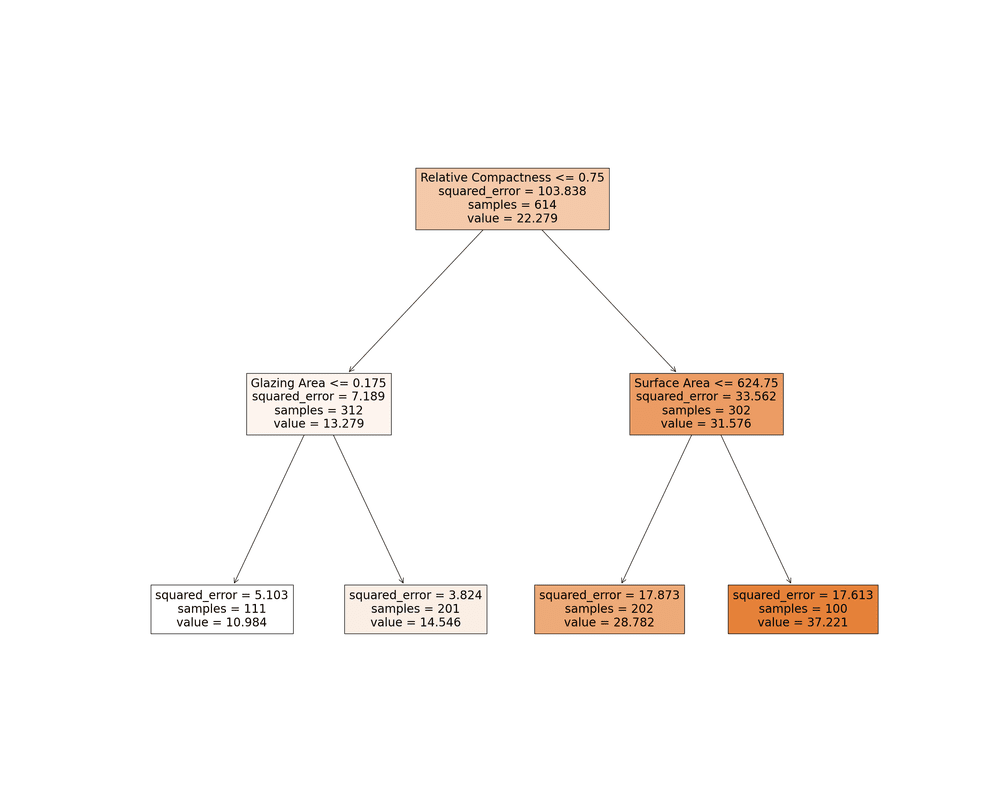
考虑计划一个户外活动,并且必须根据天气决定是否继续或取消它。决策树可用于表示此决策过程。
机器学习 (ML) 领域的决策树方法会询问一系列关于数据的二进制问题(例如,“它是否沉淀?”),直到做出决定(继续收集或停止收集)。当我们需要了解预测背后的推理时,此方法非常有用。
如果你想了解更多关于决策树的信息,你可以阅读决策树和兰登森林算法(基本上是类固醇的决策树)。
B. 支持向量机 (SVM)
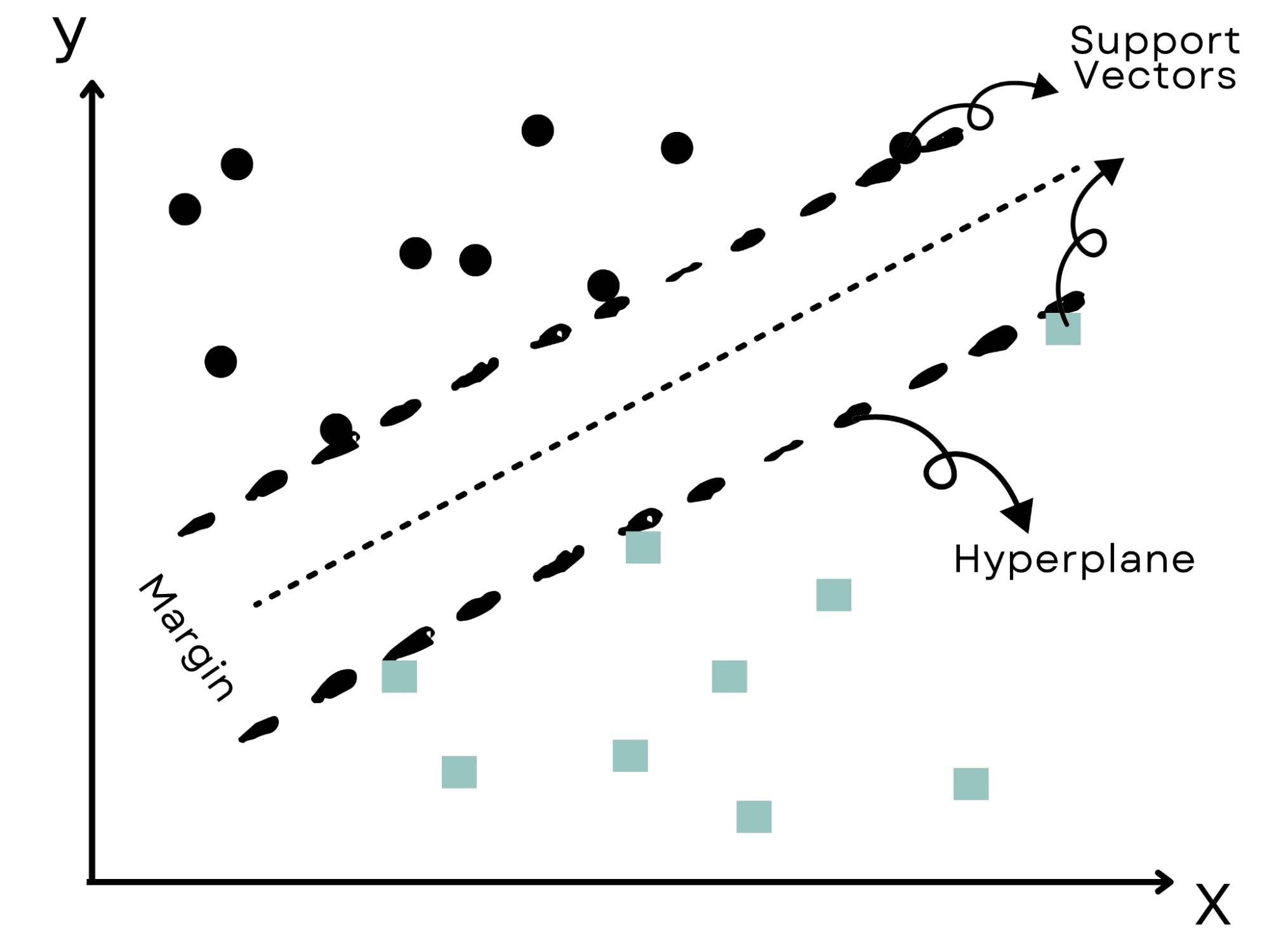
想象一下类似于狂野西部的场景,其目的是分裂两个敌对群体。
为了避免任何冲突,我们将选择最大的实际边界;这正是支持向量机(SVM)所做的。
它们确定最有效的“超平面”或边界,将数据划分为集群,同时与最近的数据点保持最远的距离。
在这里,您可以找到有关 SVM 的更多信息。
C. K-最近邻 (KNN)
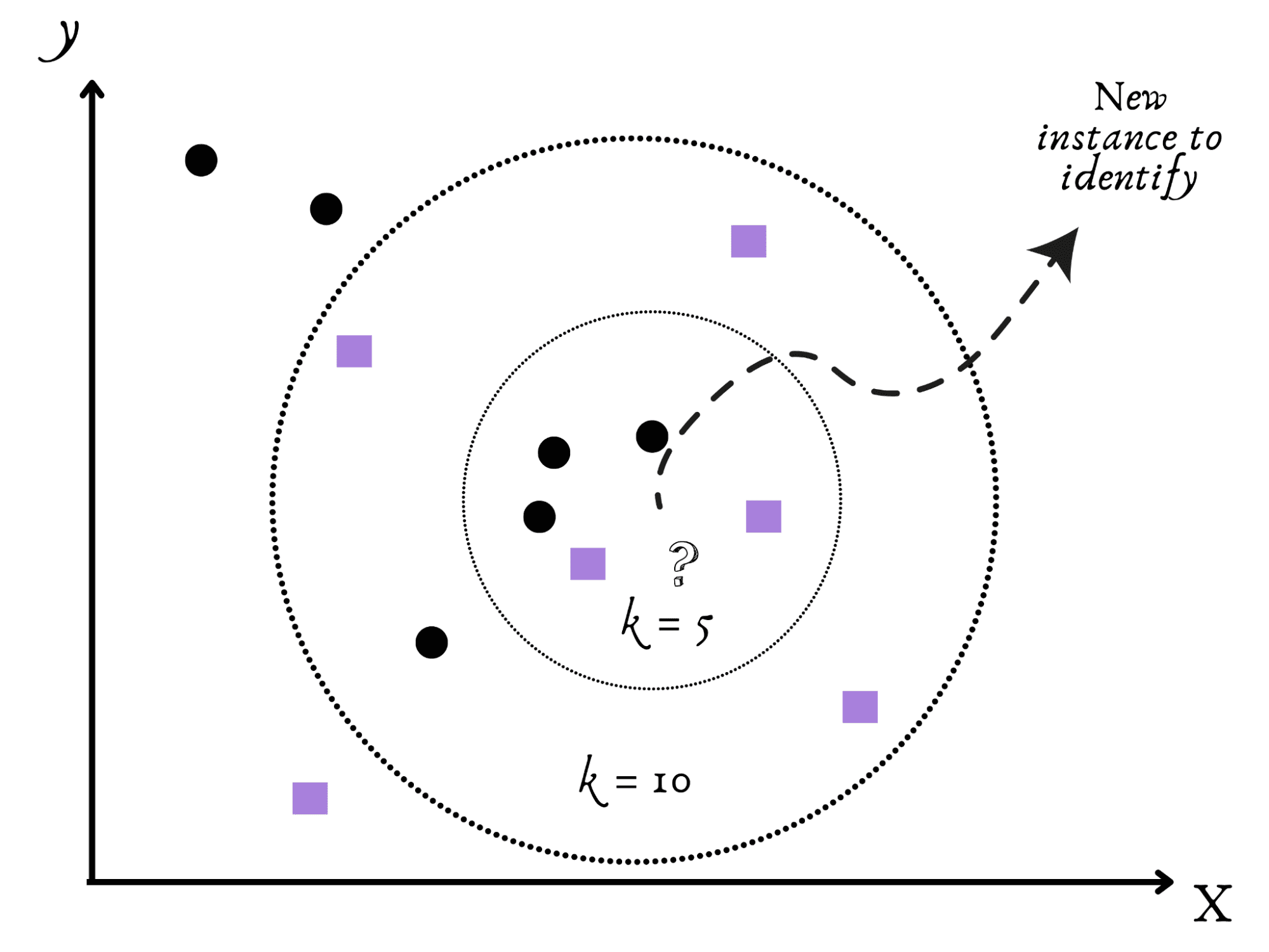
K-Nearest Neighbors(KNN)是一种友好的社交算法,紧随其后。
想象一下,搬到一个新的城镇,试图弄清楚它是安静还是繁忙。
你的自然行动方案似乎是监视你最近的邻居以获得理解。
与此类似,KNN 根据数据集中其近邻的参数(例如 k)对新数据进行分类。
在这里,您可以了解有关KNN的更多信息。
D. 线性回归
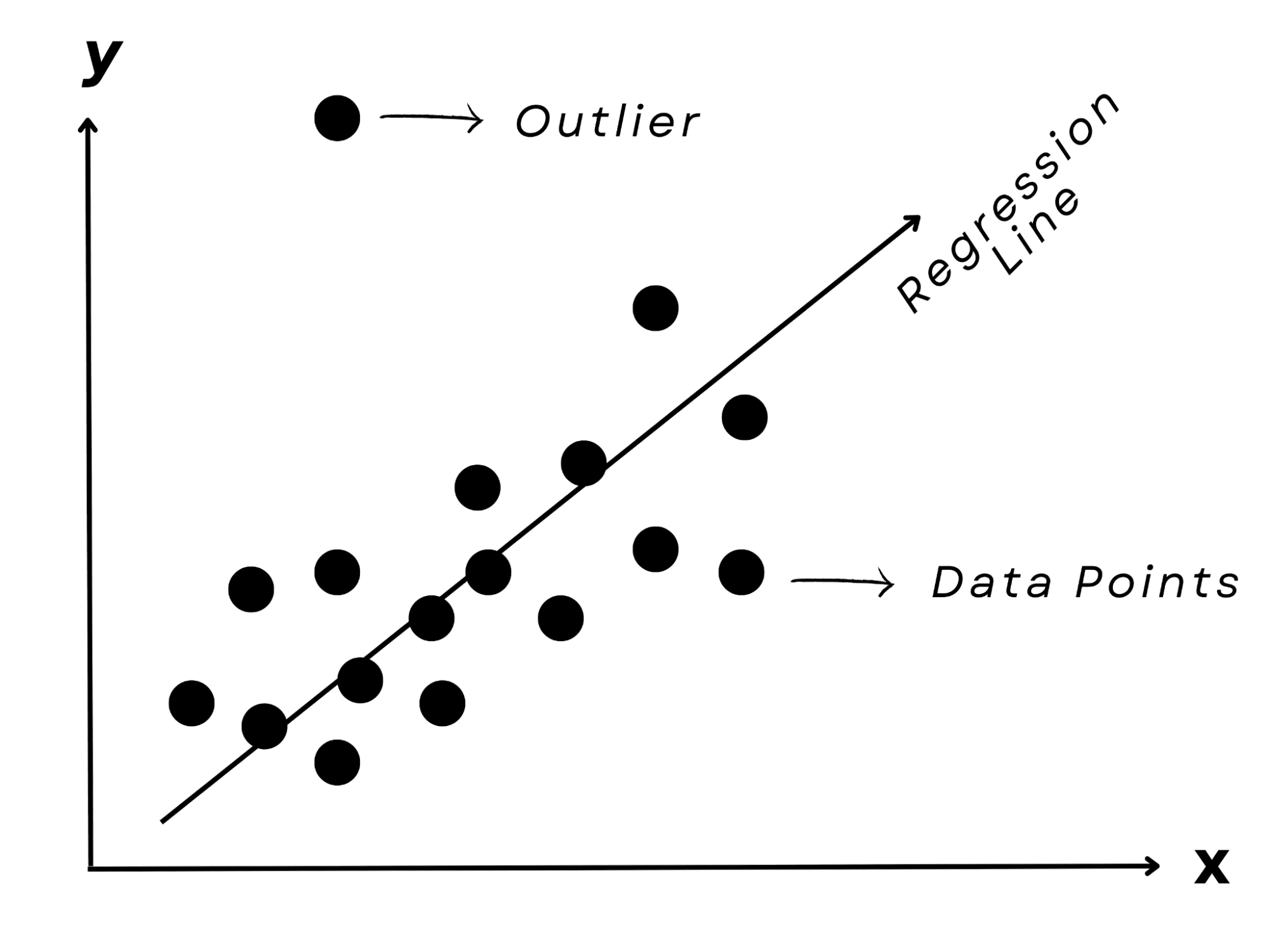
最后,想象一下试图根据朋友学习的小时数来预测他们的考试结果。你可能会注意到一个模式:花更多的时间学习通常会产生更好的结果。
线性回归模型,顾名思义,表示输入(学习小时)和输出(测试分数)之间的线性联系,可以捕获这种相关性。
它是预测数值(如房地产成本或股票市场价值)的常用方法。
有关线性回归的更多信息,您可以阅读本文。
选择正确的机器学习模型
从您可以使用的所有选项中选择正确的算法可能会感觉像试图在非常大的大海捞针中找到一根针。但别担心!让我们用一些重要的事情来澄清这个过程。
A. 了解您的数据
将您的数据视为包含最佳算法线索的藏宝图。
- 您的数据上有标签吗?(监督学习与无监督学习)
- 它包含多少功能?(我们需要缩小尺寸吗?
- 是分类的还是数字的?(分类还是回归?)
这些问题的答案可能会为您指明正确的方向。相比之下,未标记的数据可能会鼓励无监督学习算法,如聚类。例如,标记数据鼓励使用决策树等监督学习算法。
B. 定义您的问题
想象一下,用螺丝刀打钉子;不是很有效,是吗?
可以通过明确定义您的问题来选择正确的“工具”或算法。您的目标是识别隐藏模式(聚类)、预测类别(分类)还是指标(回归)?
每种任务类型都有兼容的算法。
C. 考虑实际问题
理想的算法在实际应用中偶尔可能比理论上表现不佳。您拥有的数据量、可用的计算资源以及对结果的需求都起着重要作用。
请记住,某些算法(如 KNN)在处理大型数据集时可能表现不佳,而其他算法(如朴素贝叶斯)在处理复杂数据时可能表现良好。
D. 永远不要低估评价
最后,评估和验证模型的性能至关重要。您希望确保该算法有效地处理您的数据,类似于在购买前试穿衣服。
这种“拟合”可以使用各种度量来衡量,例如分类任务的准确性或回归任务的均方误差。
结论
我们不是走了很远吗?
与将库分类为不同类型的库一样,我们首先将机器学习领域划分为监督学习、无监督学习和强化学习。然后,为了理解这些类型中书籍的多样性,我们进一步探讨了分类、回归和聚类等属于这些标题的任务。
我们首先了解了一些 ML 算法,包括决策树、支持向量机、K 最近邻、朴素贝叶斯和线性回归。这些算法中的每一种都有自己的专长和优势。
我们还意识到,选择正确的算法就像为一个零件铸造理想的参与者,同时考虑数据、问题的性质、实际应用和性能评估。
每个机器学习项目都提供了一个独特的旅程,就像每本书都给出了一个新的叙述一样。
请记住,学习、实验和改进比第一次就做对更重要。
所以做好准备,戴上你的数据科学家帽,开始你自己的ML冒险吧!
由3D建模学习工作室 整理翻译,转载请注明出处!