从噪音到艺术:了解机器学习中的扩散模型
扩散模型能够生成您能想象到的任何图像。任何!甚至是伟大的毕加索风格的狗的肖像!但它们的力量并不止于此,而是生成图像。截至最近,它们可以生成视频并帮助您通过修复和复绘完全更改自己的照片,而无需您具备 Photoshop 技能。

在线工具推荐:三维数字孪生场景工具 - GLTF/GLB在线编辑器 - Three.js AI自动纹理化开发 - YOLO 虚幻合成数据生成器 - 3D模型在线转换
什么是扩散模型?
扩散模型是一种基础模型,可以根据训练数据(训练数据)生成新数据。它们的工作原理是向图像添加高斯噪声,这本质上是影响原始图像的随机像素或失真变化。这个过程称为前向扩散过程。然后,扩散模型学会在反向扩散过程中消除这些增加的噪声,逐渐降低噪声水平,直到产生清晰和高质量的图像。
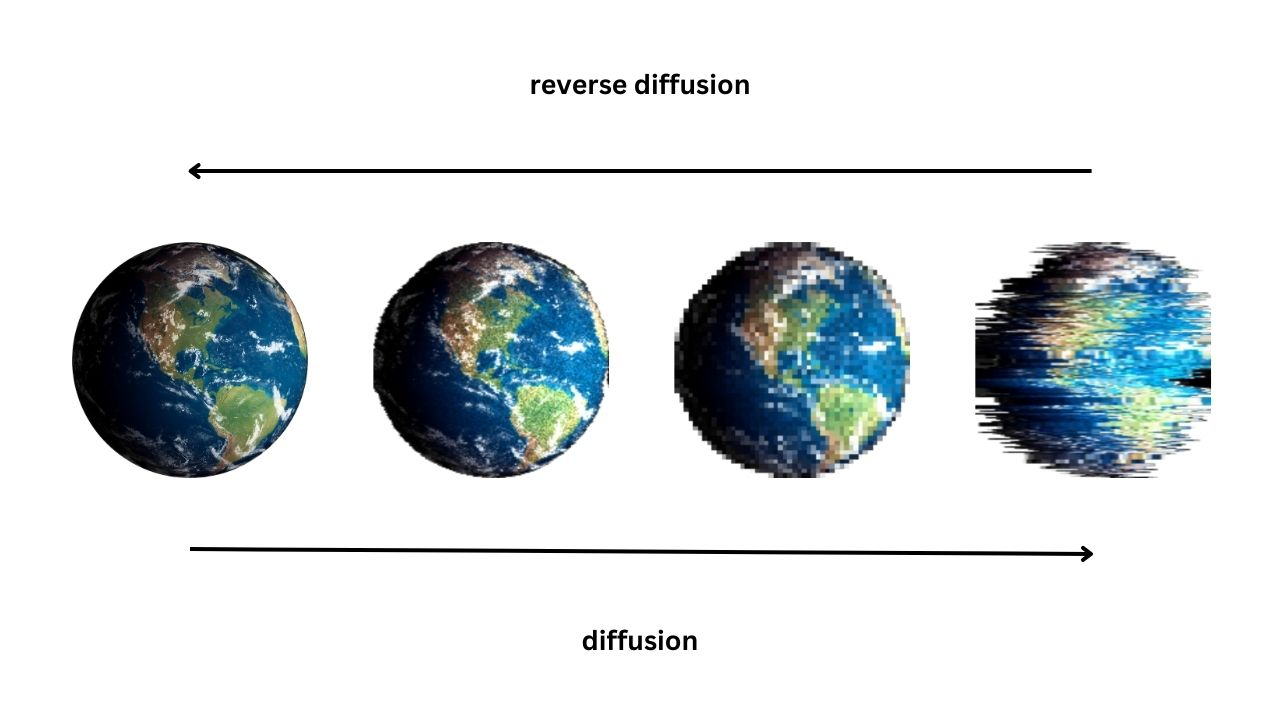
可以把它想象成在电视屏幕上添加一层静电或失真,然后模型学习如何去除静电以恢复原始图像。通过这样做,扩散模型可以生成新的高质量图像,这些图像与原始图像相似但略有不同,从而产生各种可能的输出。与其他方法和模型相比,该过程有助于扩散模型创建更多样化和更稳定的图像。
扩散模型背后的 AI 原理
为了更好地理解扩散模型的工作原理,以及它们如何能够根据我们的文本输入生成图像,我们首先需要详细说明一些技术术语。
创成式建模

从本质上讲,生成模型是一种人工智能,它可以学习如何创建新内容(生成图像或文本),这些内容看起来或听起来像它以前从训练数据中看到的东西。
生成模型包括生成对抗网络 (GAN)、变分自动编码器 (VAE)、基于转换器的大型语言模型 (LLM) 和扩散模型。扩散模型是生成模型领域的一个相对较新的补充。
计算机视觉

该术语指的是人工智能的一个领域,专注于让计算机以与人类相同的方式“查看”和理解图像和视频。它通常与生成模型结合使用,以帮助模型学习生成看起来逼真并遵循视觉世界物理规则的图像或视频。
扩散模型不像 GAN 和 VAE 那样使用计算机视觉。扩散模型依赖于一种称为基于分数的生成建模的不同技术。
基于分数的生成建模
基于分数的生成建模用于扩散模型以提高其性能。在这种建模中,扩散模型被训练为测量从现有数据生成新图像的可能性。这称为评分函数。通过从此功能训练和采样算法,模型可以生成看起来与现有数据相似的新图像。它被认为比其他方法更稳定。
潜在空间
潜在空间是表示数据抽象特征的数学空间。在生成模型的情况下,潜在空间是模型学习将现有数据映射到新的类似数据的地方。它是一个虚拟空间,其中相似的图像或文本由扩散模型分组在一起,因为它根据它们的共同特征进行学习。这有助于扩散模型生成看起来真实的图像。
高斯噪声

高斯噪声是一种随机噪声,通常添加到扩散模型的输入数据中。这样做是为了帮助扩散模型学习生成与训练数据相似的新数据,即使输入不完美。噪声是使用高斯分布生成的,高斯分布是一种概率分布,用于描述在给定范围内出现不同值的可能性。
在输入数据中添加高斯噪声可以帮助模型学习识别对输入中的微小变化具有鲁棒性的模式。高斯噪声还可用于机器学习中的其他目的,例如正则化或数据增强。
逆向扩散过程
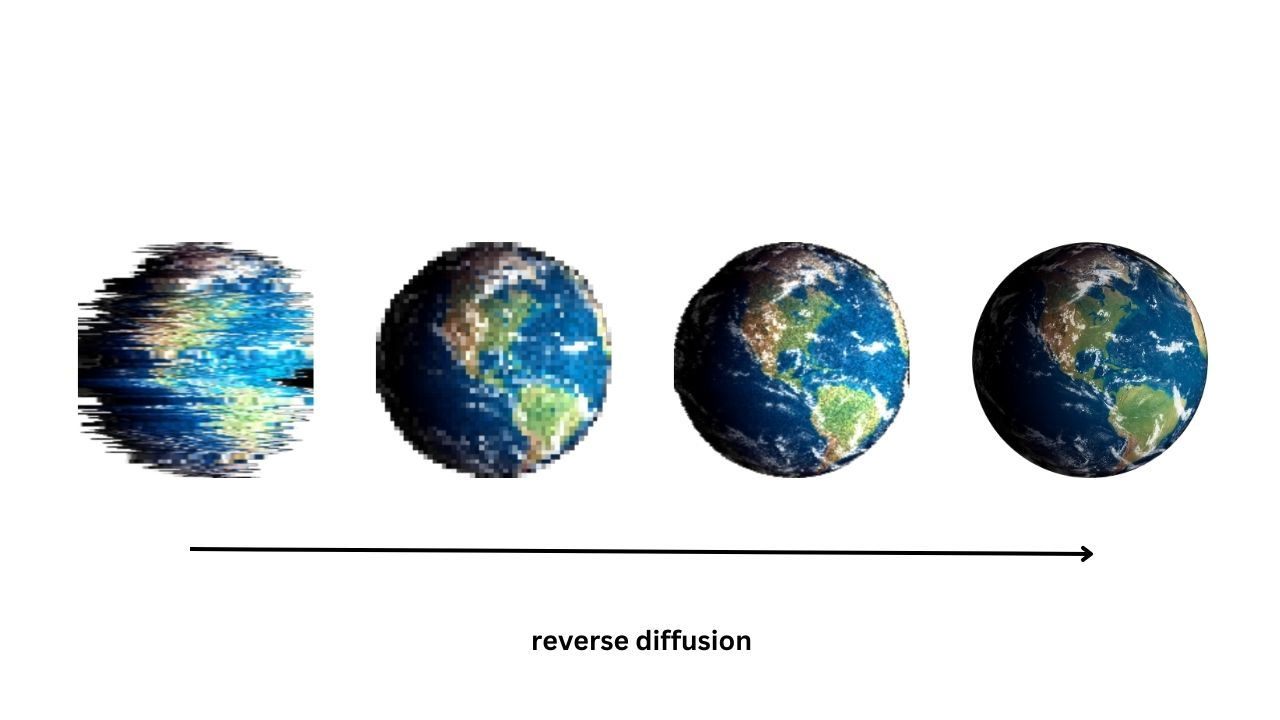
在扩散模型的上下文中,反向过程是指扩散模型能够获取噪声或退化的图像并“清理”以创建高质量图像的能力,如上图所示。这是通过反向运行图像通过扩散过程来完成的,从而消除了添加的噪声。
数据分布
扩散模型依赖于大量的数据来生成高质量的图像,而生成的图像的质量取决于数据分布的多样性和质量。通过分析数据分布,模型可以学习生成准确反映输入数据特征的图像。这在生成式建模中尤为重要,因为生成式建模的目标是创建与原始数据分布相似的新数据。
快速工程设计
扩散模型需要提示来控制其输出。您对模型输出的满意度将取决于提示的精度。提示由框架、主题、样式和可选种子组成。为了达到预期的结果,必须进行快速工程试验。建议从简单的提示开始,根据需要进行调整。有关此主题的更多信息,请阅读我们的提示工程文章。
扩散模型的特征
那么,是什么让扩散模型如此病毒式传播,并且比它们的前辈更好呢?
扩散模型是机器学习中用于图像合成和降低噪声的非常强大的工具。这种模型能够生成高质量的图像,这使其成为零售和电子商务、娱乐、社交媒体、AR/VR、营销等未来应用的一个有前途的研究领域。
扩散模型与其前辈不同,因为它们使用扩散过程来生成高度逼真的图像,并且比 GAN 更好地匹配真实图像的相同数据点分布。这意味着该过程有助于使图片更加多样化和稳定,并且不太可能看起来相同。
扩散模型可以基于各种输入进行调节,例如文本、边界框、遮罩图像和较低分辨率的图像。它们还可用于超分辨率和类条件图像生成。
扩散模型示例
所有基础模型中最新的,以及一些最先进的扩散模型,已迅速成为该镇的话题。从版权讨论到对人工智能生成的艺术超越人类创造力的担忧,DALL-E 2 和稳定扩散等扩散模型已成为头条新闻。DALL-E 2 和 Stable Diffusion 并不是唯一的,但它们是市场上最好的 AI 艺术生成器之一。
像这样的扩散模型工具使初学者可以轻松进入图像生成、修复和外绘的世界。每个平台都允许新用户通过一定数量的积分免费试用来测试其功能。
达尔-E 2
DALL-E 2 是 OpenAI 的产物,被开发为一种大型语言模型,用于从文本输入生成图像。它一直是关于 AI 艺术生成器的众多头条新闻的明星。
DALL-E 2 使您能够从输入的几句话中获得独特的图像。Dall-E 2 提供了一个简单的用户界面,没有太多多余的装饰,可以生成图像、修复和修复。该模型使用一种称为文本到图像合成的过程,该过程使其能够了解各种视觉概念并生成具有复杂细节的相应图像。
DALL-E 2 具有巨大的潜力,尤其是在广告和娱乐等行业,该模型可用于生成个性化的艺术和图像。随着 OpenAI 进行新的研究和开发新的工具,我们还没有看到 DALL-E 的全部可能性。
稳定扩散

Stable diffusion 是一种 AI 模型,可以从文本描述中生成高质量的图像。它的工作原理是获取起始图像并逐渐对其进行细化,直到它与给定的描述匹配,并具有许多参数。这个过程被称为文本到图像合成,可用于创建各种图像,包括逼真的照片和抽象艺术。
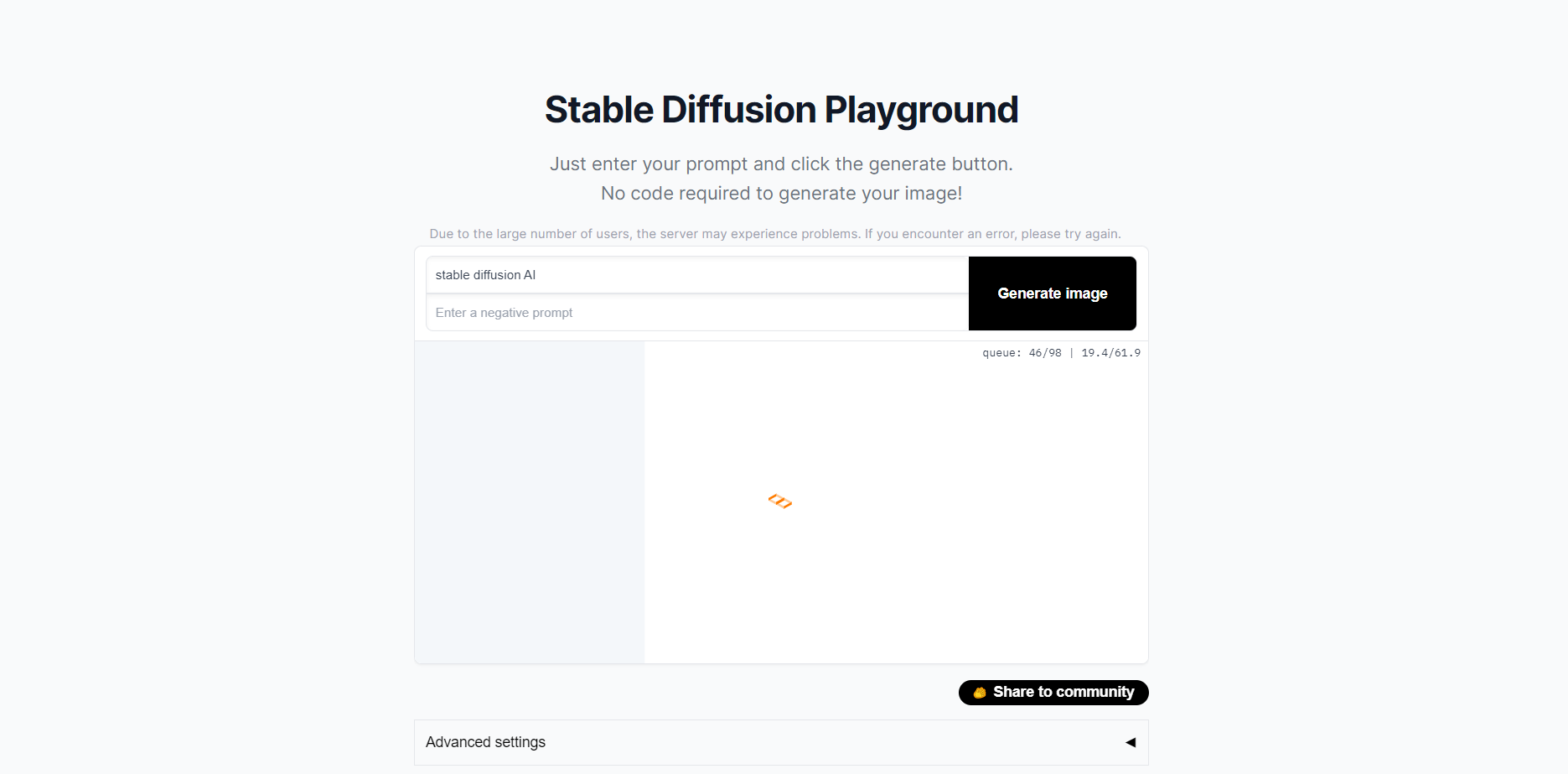
Stable Diffusion 允许您通过调整多个参数来控制生成图像的细节水平和复杂性。这种扩散模型有许多潜在的应用,包括创建个性化的艺术,为视频游戏和电影生成逼真且制作成本更低的图像,甚至帮助科学家可视化复杂数据。

使用扩散模型的方法
从图像生成、修复和外绘制到视频生成,扩散模型的可能性很多。这些工具可以帮助您恢复旧照片,添加、删除或替换图像中的人物和物体,或者完全更改图像,几乎没有照片购物技能!
修复
修复是一种先进的图像编辑技术,允许用户通过将图像的特定区域替换为扩散模型生成的新内容来修改图像的特定区域。此模型使用来自周围像素的信息来确保生成的内容无缝地适合原始图像的上下文。
与简单地擦除或遮罩图像某些区域的传统编辑工具不同,修复会生成全新的内容来填补缺失的区域。此过程同样适用于真实世界或计算机生成的图像,可用于在各种应用中增强图像。例如,您可以使用修复来修改旧婚礼(您的加号是前任)的全家福,方法是将图像的某些部分替换为扩散模型生成的新内容。







修复也用于修复旧照片,其中图像的某些部分可能随着时间的推移而褪色或损坏。通过将蒙版应用于受损区域并使用修复,扩散模型可以生成新内容来填充图像的缺失部分。这有助于将照片恢复到原始质量,并使其看起来像是最近拍摄的。

喷漆
通过outpainting,用户可以通过在图像的原始边界之外添加视觉元素,保持相同的风格,甚至将叙事推向新的方向,从而扩展他们的创作可能性。它的工作原理是从真实世界或生成的图像开始,然后对其进行扩展,直到它成为一个更大、更连贯的场景。例如,对于一个输入图像,您可以在外部边界上选择一个区域,并生成提示,以创建与原始图像一致的扩展场景。



为了生成连贯的场景,Outpainting 需要对提示进行更多优化,但它允许创建更大、更复杂的图像,而使用传统的图像编辑方法创建这些图像需要更长的时间。这将图像生成提升到一个全新的水平!
视频生成
图像扩散模型已被用于生成高质量的图像,现在该技术正在扩展到视频生成。Meta 和谷歌最近宣布了使用扩散模型根据文本提示生成短视频剪辑的 AI 系统。这些模型使用计算机视觉和基于分数的生成建模来创建大约五秒长的高质量视频。
图像策展
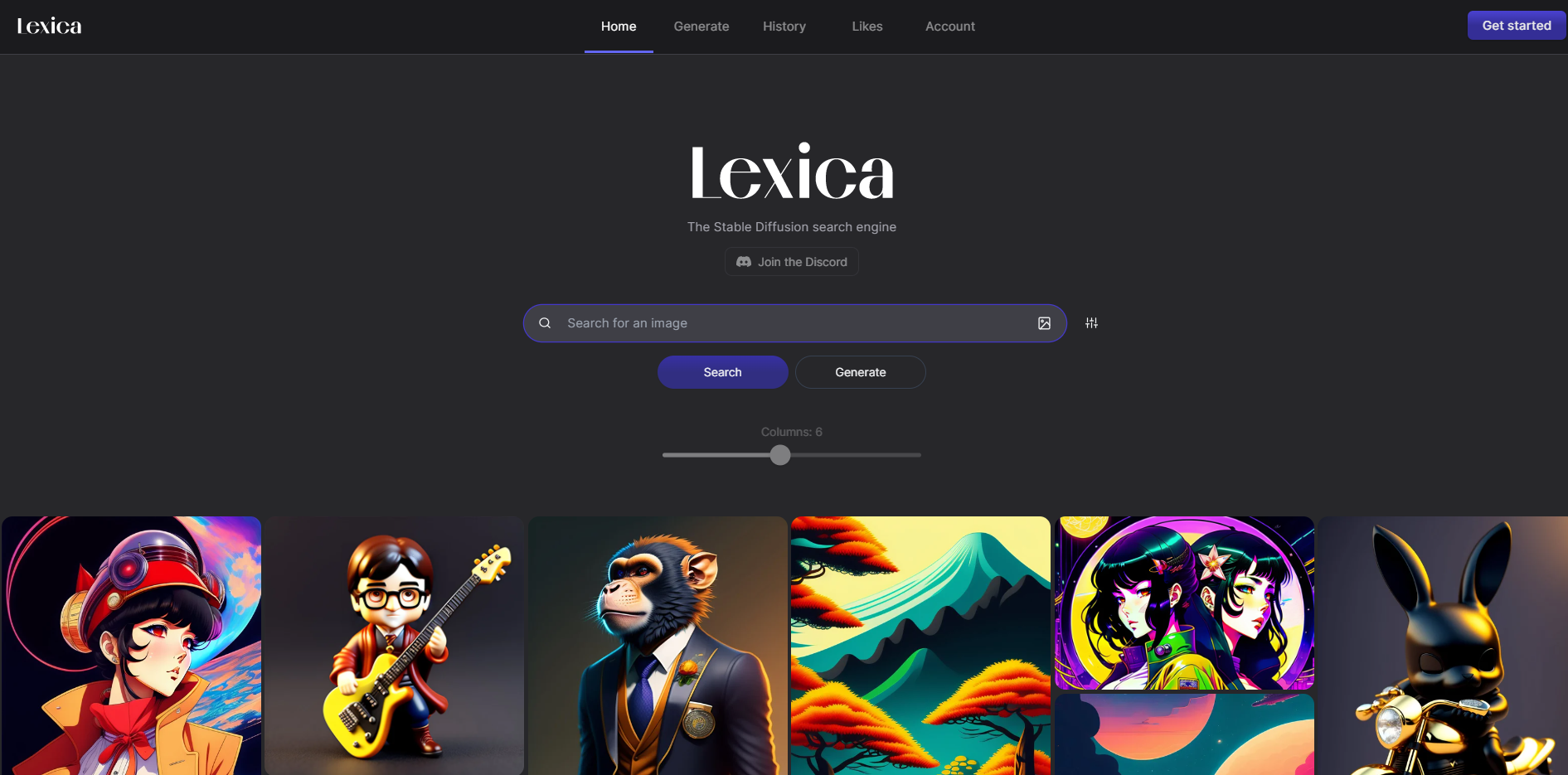
如果您正在寻找生成的图像及其相关提示的集合,您可能会发现像 Lexica.art 这样的扩散模型图像管理网站很有帮助。这些网站有数百万张图像被索引,并提供高度策划的收藏,因此您想要的图像很有可能已经存在,只需快速搜索即可。与使用扩散模型生成图像不同,搜索延迟低,您几乎可以立即获得图像。
这非常适合免费进行实验、探索提示或搜索特定类型的图像。此外,这些网站对于学习如何使用扩散模型以及如何编写提示以一次性生成所需图像非常有用。
最后的思考
扩散模型通过提供强大的工具(如 DALL-E 2 和 Stable Diffusion)进行图像合成和降噪,彻底改变了创成式建模领域。它们能够生成非常多样化和稳定的图像,这些图像与原始数据分布相似但略有不同,从而提供了广泛的可能输出。
这些模型依赖于基于分数的生成建模、潜在空间、高斯噪声和反向扩散过程等技术术语,这使它们能够创建高质量的图像。此外,扩散模型目前在零售、电子商务、娱乐、社交媒体、AR/VR 和营销等各个领域都很有用,随着时间的推移,随着许多企业利用它们来提供个性化内容,我们只会越来越多地看到它们的可能性。
随着越来越多的企业发现扩散模型在帮助解决他们的问题方面的力量,很可能会出现新的职业类型,其中之一就是“提示工程师”。