SAM + 用于文本到图像修复的稳定扩散
在本文中,我们将利用计算机视觉的第一个基础模型 SAM 的强大功能,以及流行的生成式 AI 工具 Stable Diffusion 来创建一个文本到图像的修复管道。

推荐基于稳定扩散(stable diffusion) AI 模型开发的自动纹理工具:DreamTexture.js自动纹理化开发包 - NSDT
什么是SAM?
今年早些时候,Meta AI 发布了新的开源项目:Segment Anything Model (SAM),在计算机视觉界引起了另一次巨大轰动。但是,是什么让 SAM 如此特别?
SAM 是一个可及时分割的系统,其结果简直令人惊叹。它擅长对不熟悉的物体和图像进行零样本泛化,而无需额外的培训。它也被认为是计算机视觉的第一个基础模型,这是个大新闻!接下来我们将更多地讨论基础模型。
SAM 在包含 11 万张图像和 1 亿个分割掩码的庞大数据集上进行了训练,Meta 也公开发布了该数据集。但是,展示 SAM 突破性功能的最佳方式可能是通过简短的演示:

什么是基础模型?
基础模型是在大量未标记数据集上训练的神经网络,用于处理各种任务。这些强大的机器学习算法为当今使用的许多最流行的生成式 AI 工具提供支持,包括 ChatGPT 和 BERT。
基础模型在自然语言处理方面取得了重大进展,但直到最近,在计算机视觉应用中还没有获得太大的牵引力。这是因为计算机视觉一直在努力寻找具有语义丰富的无监督预训练的任务,类似于预测 NLP 的掩码标记。借助 SAM,Meta 着手改变这种状况。
如何使用 SAM
Segment Anything 模型不需要额外的训练,因此我们需要做的就是提供一个提示,告诉模型在给定的输入图像中要分割什么。SAM 接受各种输入提示类型,但一些最常见的类型包括:
- 在 UI 中以交互方式提示
- 使用点或框以编程方式提示
- 使用从对象检测模型生成的边界框坐标进行提示
- 自动分割图像中的所有内容

项目概述:接地DINO+SAM+稳定扩散
然而,SAM 不仅能很好地与不同的输入类型集成。SAM 的输出掩码还可以用作其他 AI 系统的输入,以实现更复杂的管道!在本教程中,我们将演示如何将 SAM 与 GroundingDINO 和 Stable Diffusion 结合使用,以创建一个接受文本作为输入的管道,以使用生成式 AI 执行图像修复和修复。
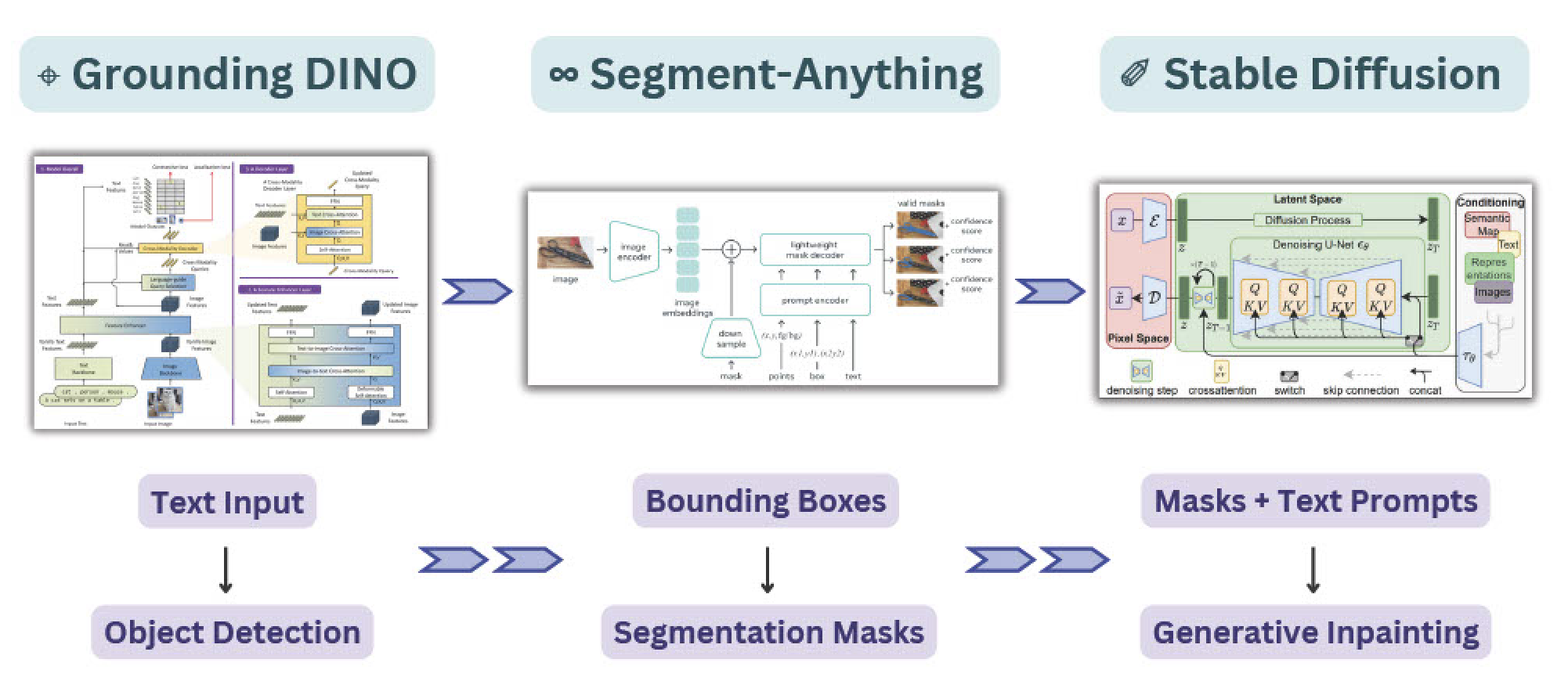
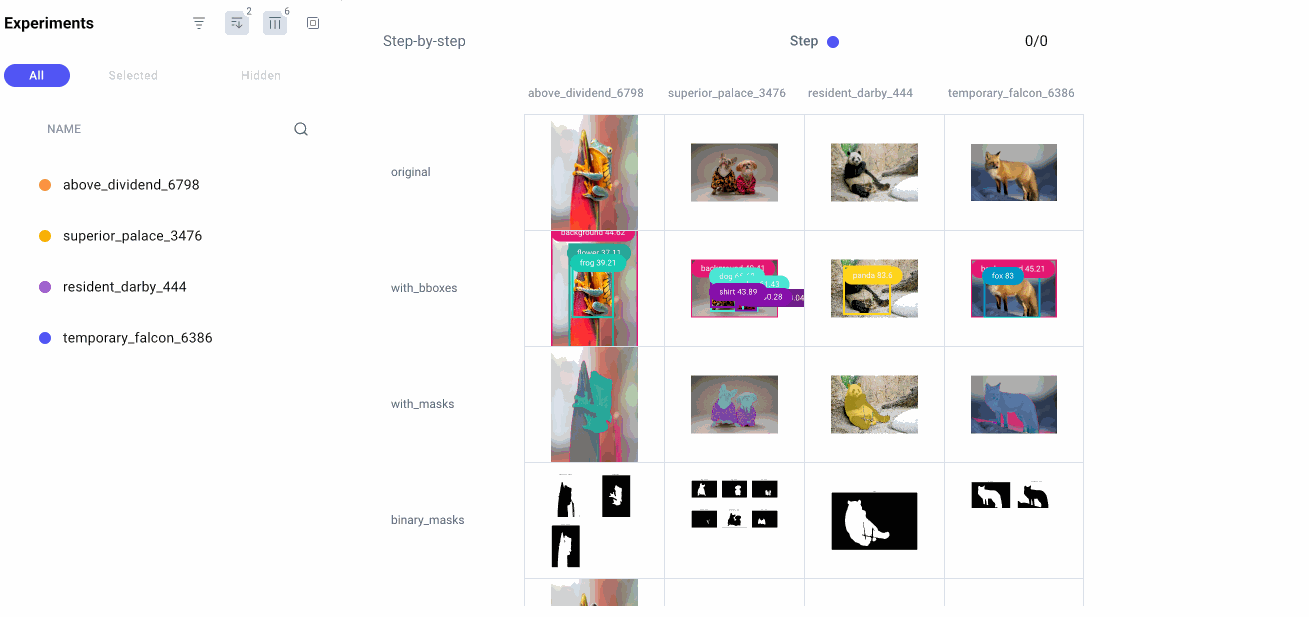
为此,我们将利用三个独立的模型。首先,我们将使用 Grounding DINO 来解释文本输入提示,并对这些输入标签执行对象检测。接下来,我们将使用 SAM 对这些边界框预测中的掩码进行分段。最后,我们将使用从 SAM 生成的蒙版来隔离图像的区域,以便使用稳定扩散进行修复或修复。我们还将使用 Comet 来记录管道中每个步骤的图像,以便我们可以准确地跟踪从输入图像到输出图像的过程。
最后,我们应该能够提供一个输入图像,一些输入文本提示,指定我们希望模型做什么,并最终得到如下所示的转换:

使用GroundingDINO进行🦕物体检测
在本教程中,我们将使用四个示例图像,可以从 Kaggle 下载。这些图片均来自 Unsplash,原始摄影师的链接可以在本博客的底部找到。

设置环境后,我们首先定义输入图像并提供文本提示,以指定要检测的对象。请注意文本提示的格式,并确保用句点分隔每个对象。我们不必在此处从任何特定类别中进行选择,因此请随意尝试此提示并根据需要添加更多类别。
经过一些非常简单的预处理后,我们使用 GroundingDINO 模型来预测输入标签的边界框。我们将这些结果记录到彗星中,以便稍后检查。这样,我们将能够看到管道中每个步骤的图像,这不仅有助于我们了解过程,还可以帮助我们在出现任何问题时进行调试。

现在,我们将使用这些边界框坐标来指示要在 SAM 中细分哪些项目。
带SAM的掩码
如前所述,SAM 可以自动检测图像中的所有掩码,也可以接受提示,引导它仅检测图像中的特定掩码。现在我们有了边界框预测,我们将使用这些坐标作为 SAM 的输入提示,并绘制生成的二进制掩码列表:

请注意,默认情况下,SAM 执行的是实例分割,而不是语义分割,这为我们提供了更大的灵活性。让我们在 Comet UI 中可视化这些蒙版:

最后,让我们隔离出要用于下一个任务的蒙版:图像修复。我们将用一个老人代替右边的狗,所以我们需要以下三个面具(我们可以从上面的二进制面具图中获取它们的索引):
用SAM隔离掩模的一部分
现在,假设我们决定要用一个老人代替右边的狗,但只是头。如果我们用点(交互或编程方式)检测面具,我们可以使用正面和负面提示将狗的脸与他身体的其他部分隔离开来,如下所示:

但是由于我们已经有了面具数组,我们将使用 np.where 隔离狗的脸。下面,我们从右边狗的面具开始,减去它的衬衫和项链的面具。然后我们将数组转换回 PIL 图像。
使用稳定扩散生成图像
在最后一步中,我们将使用 Stable Diffusion,这是一种潜在的文本到图像深度学习模型,能够在给定任何文本输入的情况下生成逼真的图像。具体来说,我们将使用 Stable Diffusion Inpainting Pipeline,它将提示、图像和二进制蒙版图像作为输入。此管道将仅针对蒙版图像的白色像素(“1”)从文本提示生成图像。
什么是修复?
图像修复是指在图像的指定区域中填充缺失数据的过程。最初,图像修复用于恢复照片的受损区域,使其看起来更像原始区域,但现在通常与蒙版一起使用,以故意改变图像的区域。
与 SAM 一样,Stable Diffusion Inpainting Pipeline 接受正负输入提示。在这里,我们指示它使用与右狗脸相对应的面具,并在其位置生成“一个卷发老人”。我们的否定提示指示模型在其生成的图像中区分特定对象或特征。最后,我们设置随机种子,以便以后可以重现结果。
专业提示:Stable Diffusion 可能会被击中或错过。如果您第一次不喜欢结果,请尝试调整随机种子并再次运行模型。如果您仍然不喜欢结果,请尝试调整提示。有关提示工程的更多信息。

这很简单!现在让我们尝试外绘。
什么是异画?
图像外绘是使用生成式 AI 将图像扩展到其原始边界之外的过程,从而生成以前不存在的图像部分。我们将通过遮罩原始背景并使用相同的 Stable Diffusion Inpainting Pipeline 来有效地做到这一点。
这里唯一的区别是输入掩码(现在是背景)和输入提示。让我们把狗带到拉斯维加斯吧!

使用稳定扩散修复多个对象
现在,让我们尝试分割图像中的多个对象。在下一张图片中,我们将要求模型同时检测青蛙和花朵。然后,我们将指示模型用考拉熊替换青蛙,并用帝国大厦替换花朵。

该模型认为花朵包括青蛙,但我们可以通过减去青蛙蒙,然后将新蒙版转换为PIL图像来解决此问题。
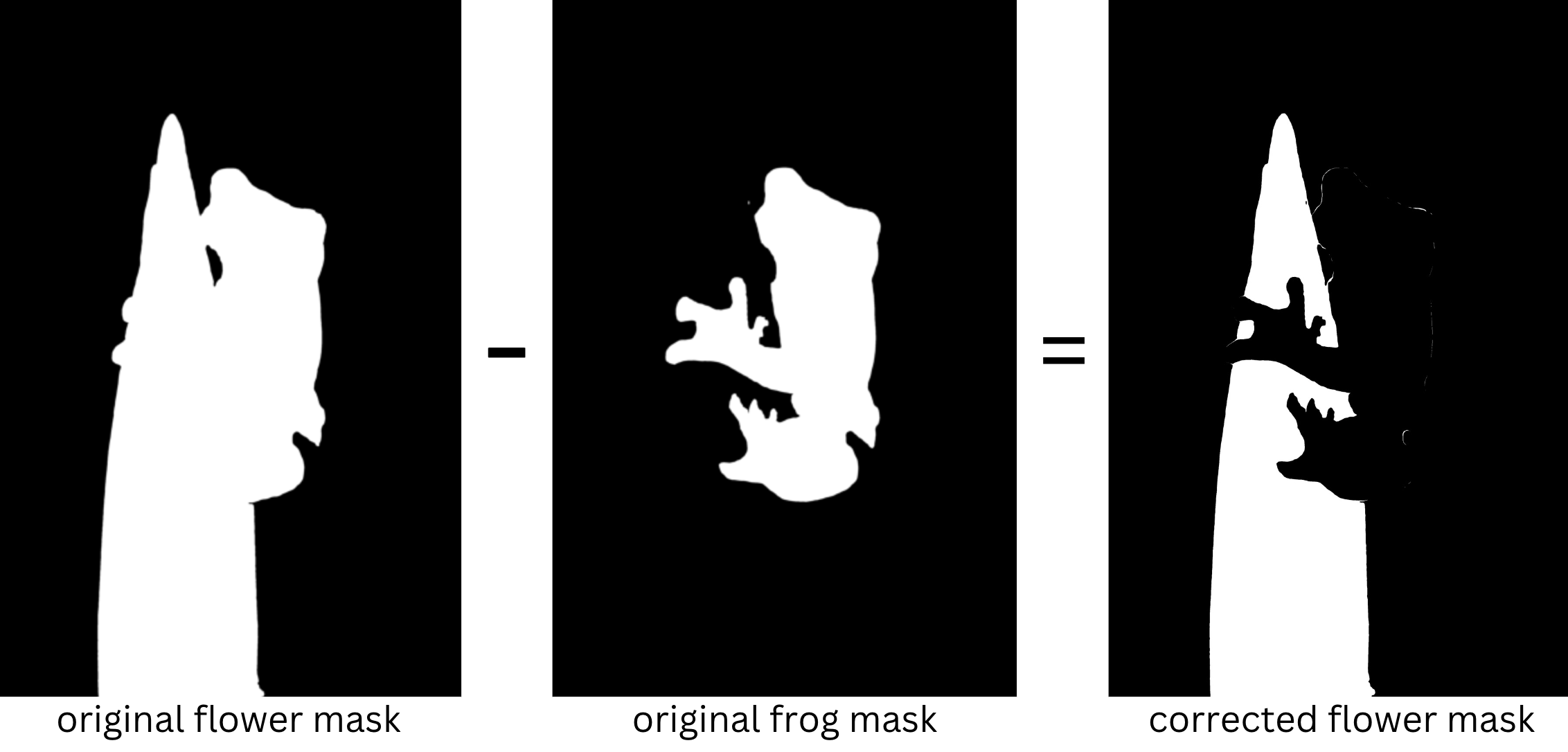
一旦我们把花分开了,让我们用帝国大厦代替它:

我们的模型并不完美;看起来我们的考拉可能还有第五条腿,摩天大楼上还有一些青蛙的残余,但总的来说,我们的管道表现相当不错!
定义稳定扩散的背景
有时我们的物体检测器GroundingDINO无法检测到背景。但是我们仍然可以很容易地进行外绘!
要在未检测到背景蒙版时创建背景蒙版,我们可以取对象蒙版的反面。如果图像中有多个对象,我们只需将这些蒙版相加,然后取此总和的倒数。
然后,我们可以遵循与前面示例中相同的过程。
在 Comet 中查看我们的 SAM + 稳定扩散结果
正如您可能想象的那样,跟踪使用哪些输入图像、提示、蒙版和随机种子来创建哪些输出图像可能会很快变得令人困惑!这就是为什么我们把所有的图像都记录到彗星上的原因。
现在让我们进入 Comet UI,看看我们的每个输入图像以及修复和修复后生成的输出图像:
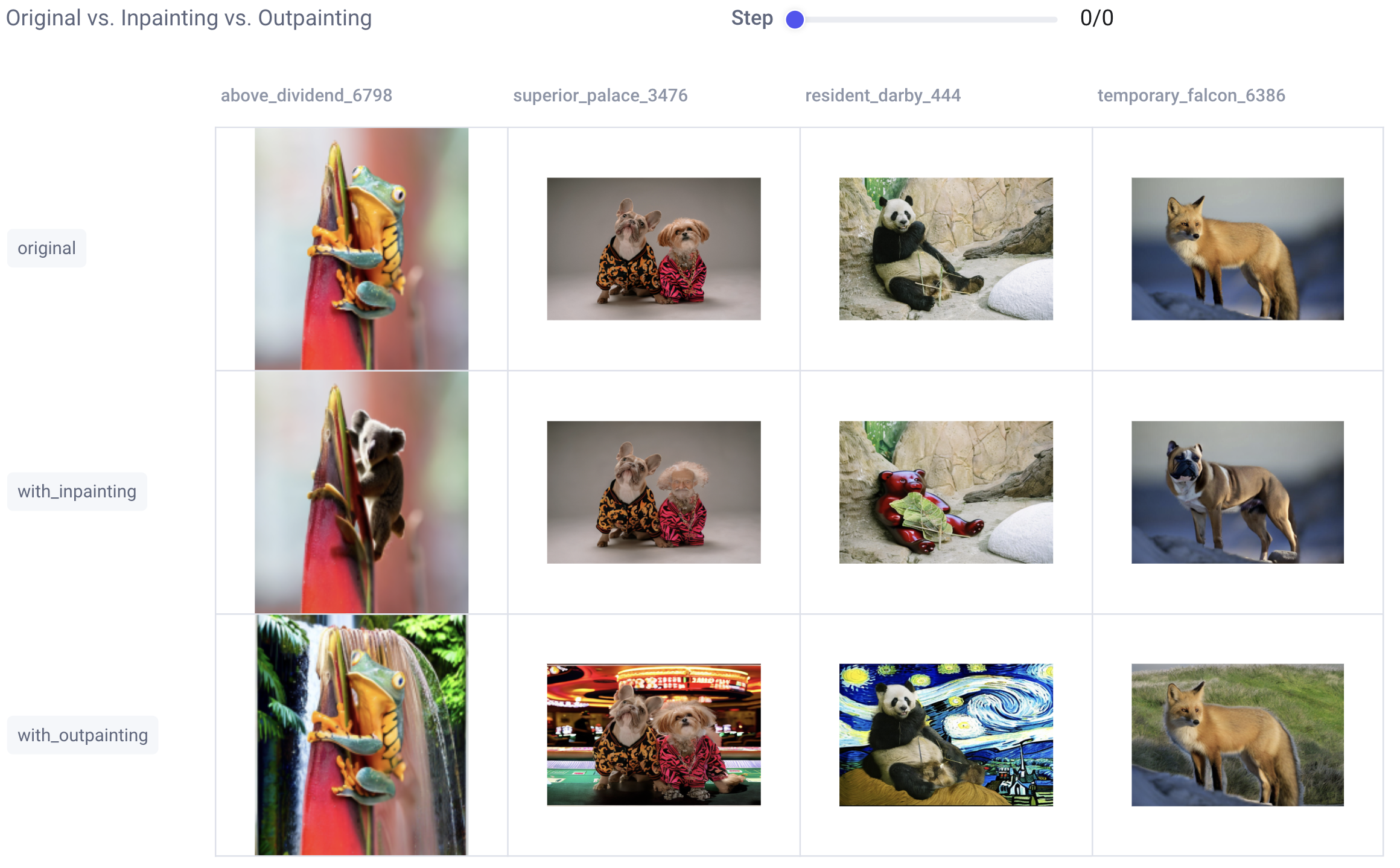
这是一个漂亮、干净的仪表板,但有时我们想更深入地了解我们是如何从 A 点到 B 点的。或者,也许,出了点问题,我们需要更深入地了解调试过程的每个步骤。为此,我们将检查自定义调试仪表板:
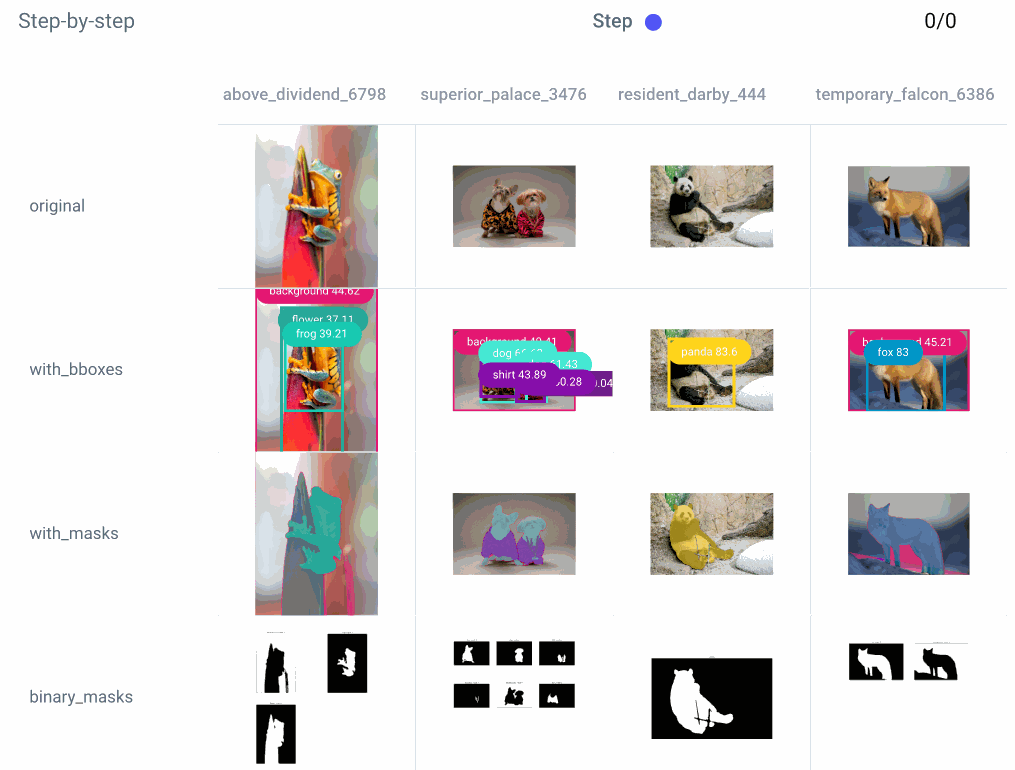
我们还可以仔细研究单个实验的每个步骤:
使用 Comet 跟踪我们的提示
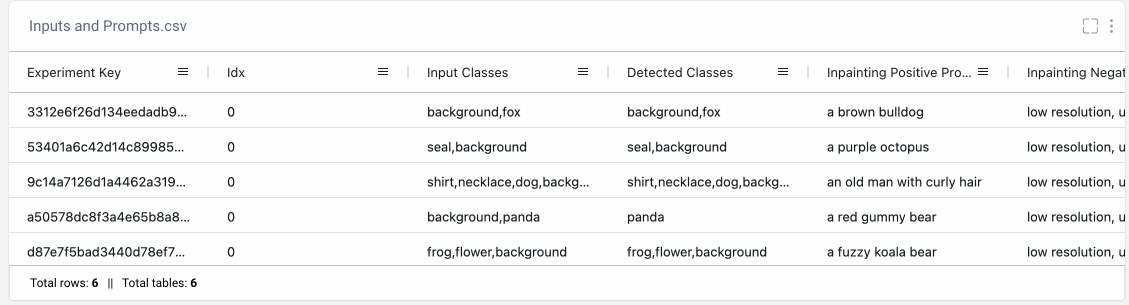
我们还需要确保跟踪我们是如何创建每个输出的,以便我们以后可以重现任何结果。也许我们已经多次运行同一提示的不同版本。或者,也许我们已经尝试了不同的随机种子,并想选择我们最喜欢的结果。通过将提示记录到彗星的数据面板,我们可以轻松检索所有相关信息,以重新创建我们的任何图像输出。
现在您已经是修复专家了,请在自己的图像上尝试管线!

结论
感谢您一直到最后,我希望您发现这个 SAM + Stable Diffusion 教程对您有所帮助!如有问题、评论或反馈,请随时在下面的评论中留言。祝您编码愉快!