稳定扩散的高分辨率图像合成
DreamTexture.js 基于 Three.js 和稳定扩散(stable diffusion) AI 模型开发,用于实现 3D 模型的自动纹理化。

推荐稳定扩散AI自动纹理工具:DreamTexture.js自动纹理化开发包
1、稳定扩散介绍
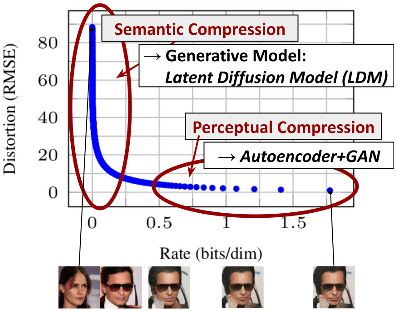
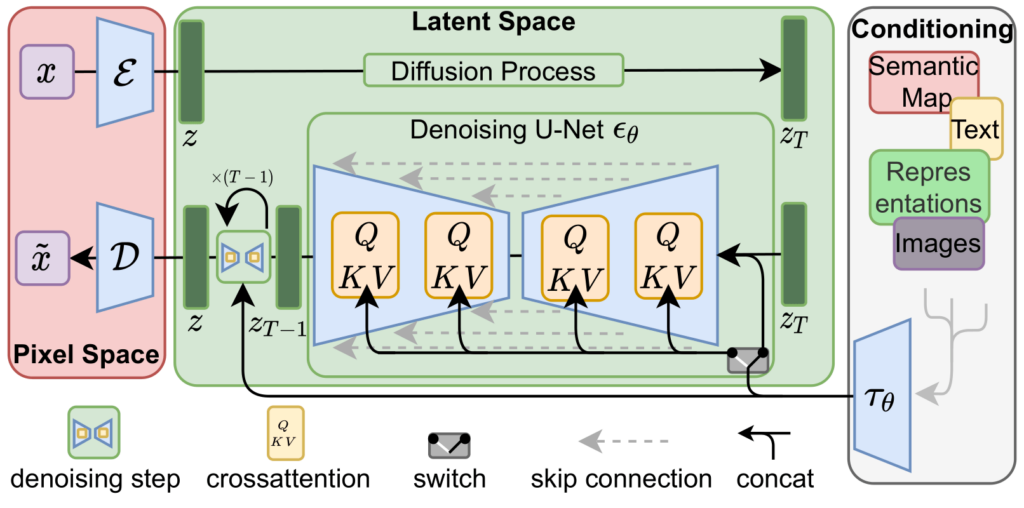
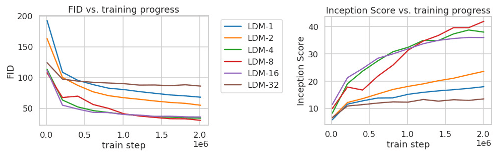
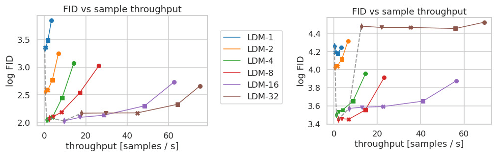
通过将图像形成过程分解为去噪自动编码器的顺序应用,扩散模型 (DM) 在图像数据及其他数据上实现了最先进的合成结果。此外,它们的配方允许将它们应用于图像修改任务,例如直接修复,而无需重新训练。然而,由于这些模型通常直接在像素空间中运行,因此优化强大的 DM 通常需要花费数百个 GPU 天,并且由于顺序评估,推理成本很高。为了在有限的计算资源上实现 DM 训练,同时保持其质量和灵活性,我们将它们应用于强大的预训练自动编码器的潜在空间。与以前的工作相比,在这种表示上训练扩散模型首次允许在复杂性降低和空间下采样之间达到接近最佳点,从而大大提高了视觉保真度。通过在模型架构中引入交叉注意力层,我们将扩散模型转化为强大而灵活的生成器,用于一般条件输入,如文本或边界框,并以卷积方式实现高分辨率合成。与基于像素的 DM 相比,我们的潜在扩散模型 (LDM) 在各种任务上都实现了极具竞争力的性能,包括无条件图像生成、修复和超分辨率,同时显注降低了计算要求。
2、基于稳定扩散的进一步研究