如何理解大语言模型中的“零镜头提示”和“少镜头提示”
在关于语言模型的文献中,你经常会遇到术语“零镜头提示”和“少镜头提示”。了解大型语言模型如何生成输出非常重要。
推荐:将NSDT场景编辑器加入你的3D工具链
3D工具集:NSDT简石数字孪生
什么是零镜头提示和少镜头提示
在关于语言模型的文献中,你经常会遇到术语“零镜头提示”和“少镜头提示”。了解大型语言模型如何生成输出非常重要。在这篇文章中,您将了解:
- 什么是零镜头和少镜头提示?
- 如何在 GPT4All 中进行实验

什么是作者使用稳定扩散生成的零镜头提示和少镜头提示
图片。保留部分权利。
让我们开始吧。
概述
这篇文章分为三个部分;它们是:
- 大型语言模型如何生成输出?
- 零镜头提示
- 少数镜头提示
大型语言模型如何生成输出?
使用大量文本数据训练大型语言模型。他们接受训练,从输入中预测下一个单词。研究发现,给定模型足够大,不仅可以学习人类语言的语法,还可以学习单词的含义、常识和原始逻辑。
因此,如果你给模型一个片段化的句子“我邻居的狗是”(作为输入,也称为提示),它可能会用“聪明”或“小”来预测,但不太可能用“顺序”来预测,尽管所有这些都是形容词。同样,如果为模型提供完整的句子,则可以期望从模型的输出中自然地遵循一个句子。重复将模型的输出追加到原始输入并再次调用模型会使模型生成冗长的响应。
零镜头提示
在自然语言处理模型中,零镜头提示意味着向模型提供不属于训练数据的提示,但模型可以生成所需的结果。这种有前途的技术使大型语言模型可用于许多任务。
要理解为什么这很有用,请想象情感分析的情况:您可以选取不同观点的段落,并用情感分类对其进行标记。然后,您可以训练一个机器学习模型(例如,文本数据上的RNN)将段落作为输入并生成分类作为输出。但你会发现这样的模型是不自适应的。如果向分类添加新类,或者要求不对段落进行分类,而是对其进行汇总,则必须修改并重新训练此模型。
但是,大型语言模型不需要重新训练。如果您知道如何正确提问,您可以要求模型对段落进行分类或对其进行总结。这意味着该模型可能无法将段落分类为A类或B类,因为“A”和“B”的含义尚不清楚。尽管如此,它仍然可以分为“积极情绪”或“消极情绪”,因为模型知道“积极”和“消极”应该是什么。这是有效的,因为在训练期间,模型学习了这些单词的含义,并获得了遵循简单指令的能力。下面是一个示例,使用 GPT4All 和模型 Vicuna-7B 进行演示:
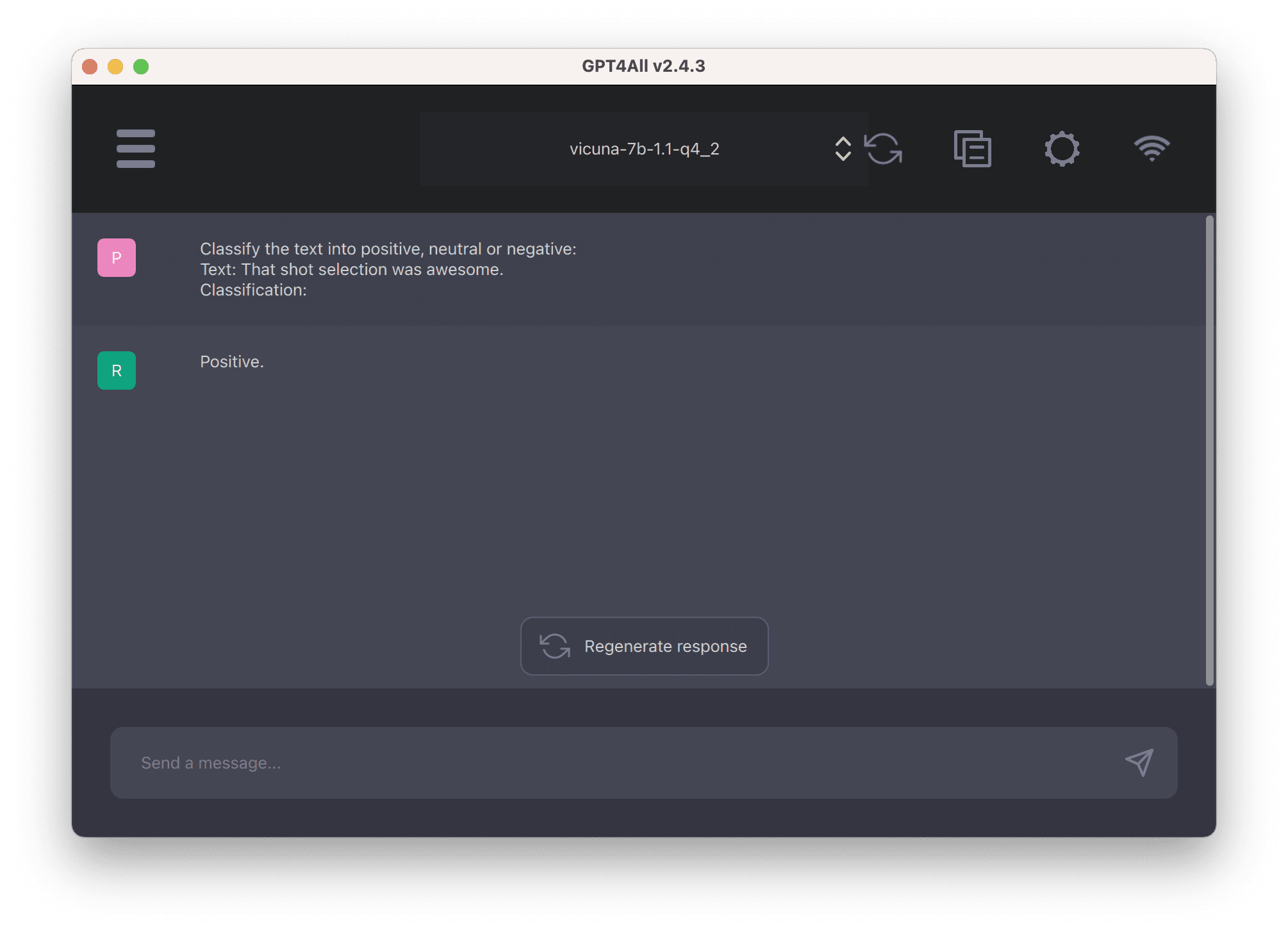
提供的提示是:
1 2 3 | Classify the text into positive, neutral or negative: Text: That shot selection was awesome. Classification: |
回答只有一个字,“积极”。这是正确和简洁的。该模型显然可以理解“很棒”是一种积极的感觉,但知道识别这种感觉是因为开头的指示,“将文本分为积极、中性或消极。
在此示例中,您发现模型响应是因为它理解您的指令。
少数镜头提示
如果你不能描述你想要什么,但仍然希望语言模型给你答案,你可以提供一些例子。使用以下示例更容易演示这一点:

在 GPT7All 中仍然使用 Vicuna-4B 模型,但这一次,我们提供提示:
1 2 3 4 5 6 7 8 | Text: Today the weather is fantastic Classification: Pos Text: The furniture is small. Classification: Neu Text: I don't like your attitude Classification: Neg Text: That shot selection was awful Classification: |
在这里你可以看到没有提供关于做什么的指令,但通过一些例子,模型可以弄清楚如何响应。另外,请注意,模型响应的是“Neg”而不是“Negative”,因为它是示例中提供的。
注意:由于模型的随机性,您可能无法重现确切的结果。每次运行模型时,还可能会发现生成的输出不同。
引导模型使用示例进行响应称为少镜头提示。
总结
在这篇文章中,您学习了一些提示示例。具体而言,您了解到:
- 什么是单镜头和少镜头提示
- 模型如何使用单镜头和少数镜头提示
- 如何使用 GPT4All 测试这些提示技术
由3D建模学习工作室 翻译整理,转载请注明出处!