利用人工智能和数字孪生技术减少发电厂温室气体排放
减少排放到大气中的碳量是一项政治优先事项。现任美国政府计划到 2035 年实现电网净零碳排放,到 2050 年实现全行业零碳排放。 为了实现这一目标,正在开发各种技术,利用人工智能的效率来对抗气候变化。对于发电厂而言,开发减少碳排放、碳捕获和储存过程的技术需要详细了解整个设施的相关流体力学和化学过程。这需要对流体力学、传热、化学反应及其相互作用程度进行科学精确的模拟。

推荐:将NSDT场景编辑器加入你的3D工具链
3D工具集:NSDT简石数字孪生
利用人工智能和数字孪生技术减少发电厂温室气体排放
减少排放到大气中的碳量是一项政治优先事项。现任美国政府计划到 2035 年实现电网净零碳排放,到 2050 年实现全行业零碳排放。
为了实现这一目标,正在开发各种技术,利用人工智能的效率来对抗气候变化。对于发电厂而言,开发减少碳排放、碳捕获和储存过程的技术需要详细了解整个设施的相关流体力学和化学过程。这需要对流体力学、传热、化学反应及其相互作用程度进行科学精确的模拟。
工业用例的一个重要重点是开发更高效的燃料转换装置。目标是创造更灵活的设备,以便设备能够以更可靠的方式与可再生资源集成。
至关重要的是要有更好的设计优化、不确定性量化和精确的数字孪生,这样才能在不造成数十亿美元损失的情况下充分处理能量转换装置的设计和控制。人工智能是一个自然的选择,可以用来开发这样的数字孪生,可以在不影响准确性的情况下提供近乎实时的预测。
这篇文章解释了物理信息机器学习( ML )框架 NVIDIA Modulus 如何与现有的流求解器结合使用,以实现大规模科学建模,并开发有助于实现净零碳排放的电厂数字孪生。
用物理 ML 模拟工业电厂
新运行条件下的流场预测,如输入条件或锅炉部件几何结构的变化,需要新的计算流体动力学模拟。如果模拟涵盖了大量的空间参数,例如用于不确定性量化研究的参数,这可能会变得非常昂贵和耗时。而且,在大多数情况下,整个流场都不重要。神经网络经过训练后,可以在几秒钟内预测受影响区域所需点的流场。
NVIDIA Modulus 的研究人员正与国家能源技术实验室( NETL )一起开发一种能够模拟湍流反应流的电厂锅炉数字孪生模型。数字孪生将使用机器学习以高逼真度复制锅炉内部的流动条件,并能够为感兴趣的操作条件提供接近瞬时的流动预测。
了解内部速度、温度和物种场对于采取措施减少温室气体和污染物的排放至关重要。物理信息 ML ,也称为物理 ML ,可用于建模预测控制,以帮助电厂操作员优化锅炉运行条件,提高效率和性能。
虽然不是本研究的一部分,但应该注意的是,数字孪生也可以用于网络安全目的,充当数字幽灵,分散入侵者对目标的注意力。这些数字重影向控制室提供系统状态的合成变化的操作条件副本。如果入侵者访问控制室数据,他们将无法区分实际操作数据和这些副本。该框架可以扩展到对其他发电厂部件进行建模,只需适度的努力。
使用实时反馈增强代理模型
代理模型还可以与来自连接到锅炉的传感器的实时反馈相耦合,以随着现场数据的同化而不断改进自身。
典型的电厂锅炉包括数十个浓度传感器、数百个温度传感器和数千个测量流量数据的传感器。应优化这些传感器的位置,以便在温度可能超过 1000 ℃的恶劣锅炉运行条件下,不会熔化或损坏这些传感器。这些传感器可以向代理模型提供数据流,以通过数据同化和在线学习不断更新模型,从而提高模型的准确性和可靠性。
此外,物理模型的参数(如反应动力学和粘度)存在很多不确定性。使用传感器数据可以通过将现场数据同化到代理模型中来减少这些不确定性。如果不考虑这些不确定性,可能会造成严重的金钱损失和数天甚至数月的停电。
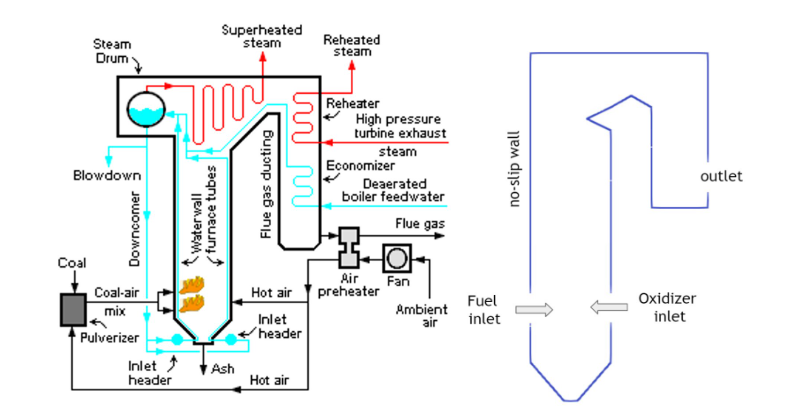
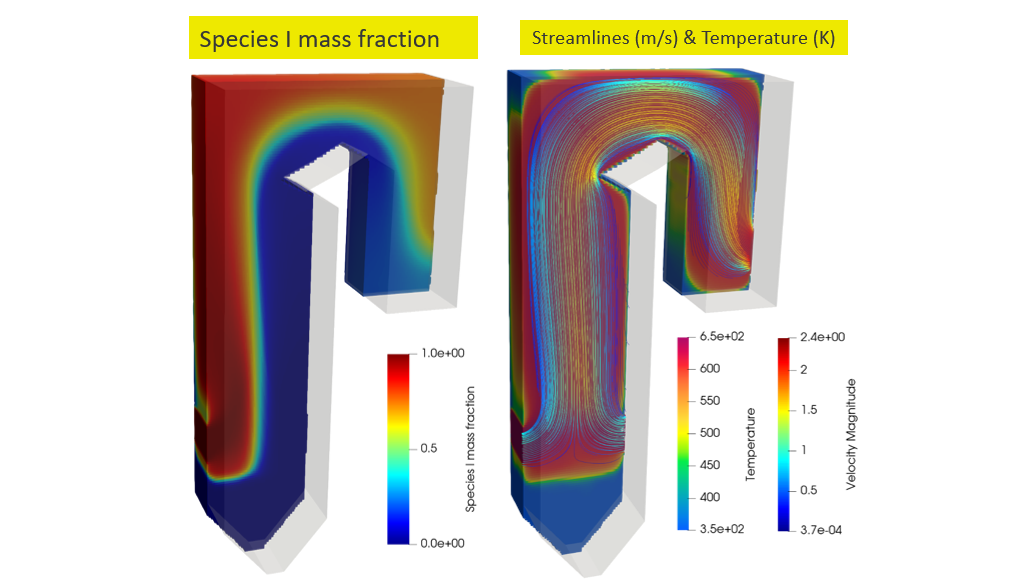
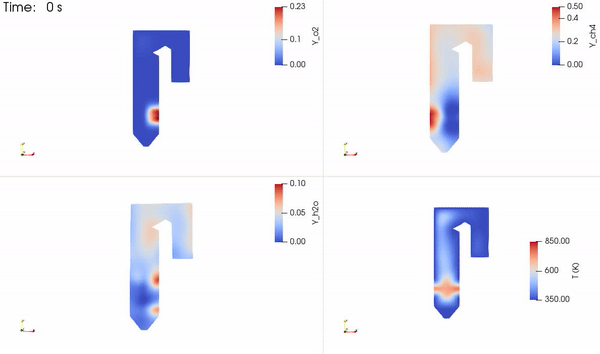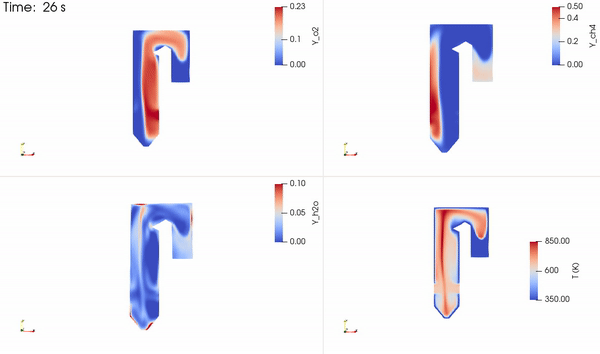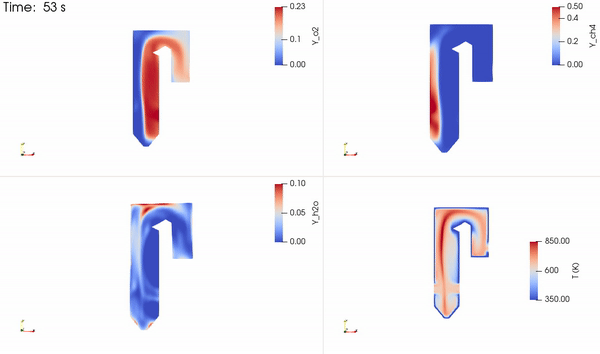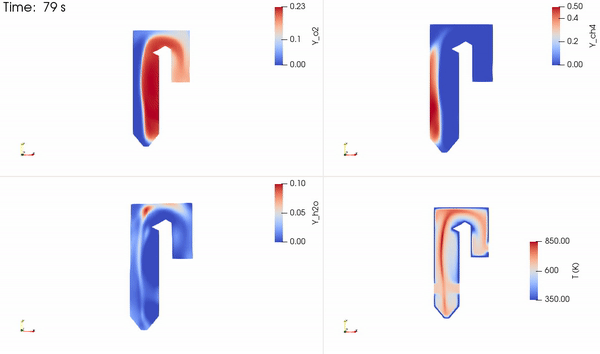
图 2 说明了本研究中用于求解甲烷和氧气反应生成二氧化碳和水的流场、温度和物质质量浓度的简化锅炉。流经锅炉管的水被加热并转化为蒸汽,蒸汽被引导通过涡轮机发电。反应产物 CO2 和 H2O 被释放到空气中。如果被捕获,它们可以被注入地下。
氧化剂入口速度直接控制锅炉内的流动条件,进而控制其效率和性能。氧化剂输入速度的变化影响锅炉内的燃烧过程,进而影响整个系统的温度和物种分布。
控制锅炉内部的温度非常重要,因为它直接影响工作流体的温度和状态,在本研究中,工作流体是水。这一点非常关键,必须满足锅炉外部不同部件(包括水管和涡轮机)的热约束。
此外,氧化剂入口速度控制每单位时间进入反应器的空气量,这直接影响物种的停留时间和总体混合行为。如果停留时间太短,则反应可能无法在锅炉内正确发生,如果停留时间太长,则可能发生导致过量污染物排放的额外反应,如 CO 、 NOx 和 CO2 。因此,入口速度是优化燃烧过程和发电的关键变量。

如何使用物理信息 ML 构建锅炉数字孪生模型
NVIDIA Modulus 提供了一系列模型,这些模型可以纯粹基于物理或数据,或数据和物理的组合进行训练。通过参数化这些模型,并利用优化的推理管道, NVIDIA Modulus 能够预测不同操作和环境条件下的系统行为,作为后处理步骤。
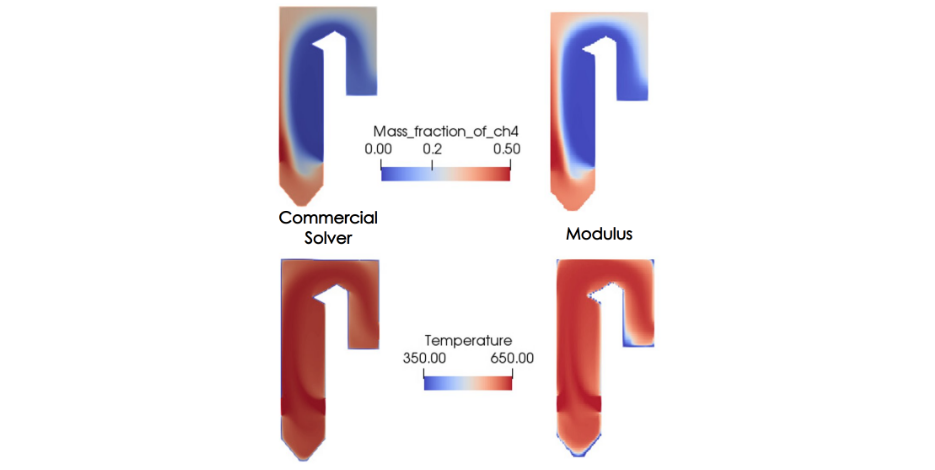
如前所述, NVIDIA Modulus 被用于开发一个参数化模型,该模型基于普通锅炉的物理控制规律进行训练。经过训练后,该模型可提供锅炉内部温度、物种质量浓度、流速以及任何给定物种入口速度下的压力的近瞬时预测。不使用训练数据,损失函数仅根据神经网络解满足控制方程和边界条件的程度来制定。
对于这个问题,入口的温度被固定在 650K ,而壁的温度为 350K 。该简化情况的参数空间由变化的氧化剂入口速度跨越,其范围在 1 至 5 m / s 之间。
使用零方程公式对湍流 Reynolds stresses 进行建模。 NVIDIA Modulus 中的正弦表示网络( SiReN )用作网络架构。该网络架构的一个关键组件是初始化方案,其中网络的权重矩阵是从均匀分布中提取的。每个 Sin 激活的输入具有正态分布,每个 Sin 活化的输出具有 arcSin 分布。这保留了激活的分布,允许有效地构建和训练深层架构。
网络的第一层按因子缩放以跨越 Sin 函数的多个周期。经验表明,这提供了良好的性能,并符合傅里叶网络中输入编码的优点。 NVIDIA Modulus 的几个特征,如 L2 到 L1 损耗衰减和使用符号距离函数( SDF )的空间损耗加权,用于提高精度。通过利用 NVIDIA Modulus 性能升级(如实时( JIT )编译和 CUDA 图形),将收敛时间降至最低。
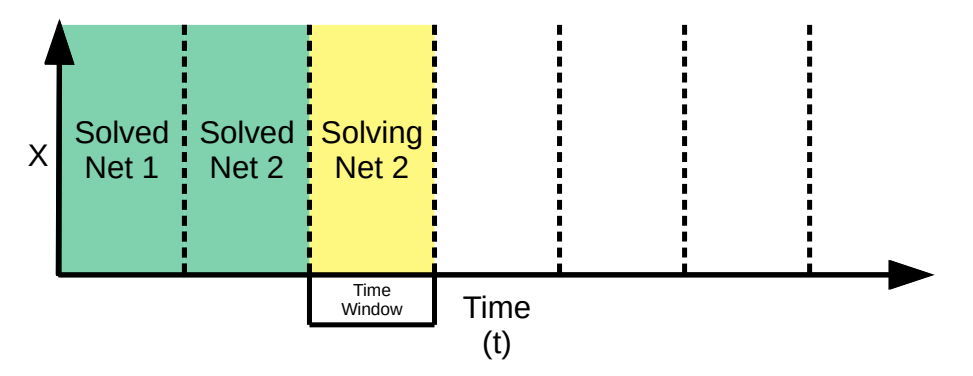
NVIDIA Modulus 团队开发的移动时间窗方法用于瞬态流建模。在长时间内,仅使用传统的连续时间方法求解瞬态模拟可能很困难。移动时间窗方法迭代求解小的连续时间窗。连续时间法用于在特定窗口内求解,每个时间窗口结束时的解用作下一个窗口的初始条件。
选择性方程项抑制
对于燃烧建模, NETL 研究人员开发的一种新方法,称为选择性方程项抑制( SETS ),被用于大幅提高训练收敛性。
对于几个偏微分方程( PDE ),物理方程中的项在时间和量级上具有不同的尺度(有时也称为刚性 PDE )。对于这样的 PDE ,尽管对较小项处理不当,损失方程似乎可以最小化。
使用 SETS 方法来解决这个问题,您可以创建同一 PDE 的多个实例并冻结某些术语。在优化过程中,这会迫使优化器使用前一次迭代中的值作为冻结项。因此,优化器最小化 PDE 中的每个项,并有效地减少方程残差。
这防止了 PDE 中的任何一项支配损耗梯度。在每个实例中创建具有不同冻结项的多个实例允许物理的整体表示保持不变,同时允许神经网络更好地学习方程中所有项之间的动态平衡。
然而,创建同一等式的多个实例(具有不同的冻结项)也会创建多个损失项,每个损失项的权重可以不同。还开发了几种其他配方来有效处理僵硬的 PDE :
- 在训练期间逐步增加源项,以使神经网络更好地适应问题。
- 通过调整物种方程和温度方程的训练顺序及其训练实例的相对数量,更好地控制它们之间的耦合。
残余归一化
用于改进训练收敛性的另一种新方法是残差归一化或重新归一化。在神经网络求解器的损失平衡中使用的主要方法是将参数乘以每个单独的损失项,以平衡每个项对总损失的贡献。然而,手动调整这些参数并不简单,还需要将这些参数视为常量。 ResNorm 最大限度地减少了一个额外的损失项,它鼓励个体损失采取类似的相对幅度。基于不同约束的相对训练速率,在整个训练过程中动态调整损失权重。
两种反应物质(产物种类和温度)的分布如图 5 所示。反应物接触形成形成产物的薄反应区。然后释放能量,提高局部温度,并在整个区域内进行平流和扩散。
与 NVIDIA Omniverse 的 3D 设计集成
NVIDIA Omniverse 是一个易于扩展的平台,用于 3D 设计协作和可扩展的多 GPU 、实时、真实模拟。 NVIDIA Modulus 的 NVIDIA Omniverse 扩展支持实时、虚拟世界模拟和全设计逼真可视化。内置管道可用于常见可视化,如 NVIDIA Modulus 模型输出的流线和等值线。
这种集成的另一个好处是,当设计参数变化时,能够近实时地可视化和分析高保真仿真输出。在电厂锅炉项目的最后部分, NVIDIA Modulus 的 NVIDIA Omniverse 扩展将用于开发一个锅炉数字孪生模型,该模型使用最终训练的模型,在不同的运行条件下,对锅炉内的流量、温度、压力和物质质量浓度进行近瞬时预测和可视化。

3D建模学习工作室 翻译整理,转载请注明出处!