如何正确使用生成式 AI?
如何正确使用生成式 AI?

推荐:使用NSDT场景编辑器助你快速搭建可二次编辑的3D应用场景
在过去几年中,数据的创建速度呈指数级增长,这主要意味着数字世界的日益扩散。
估计吧?仅在过去两年中,世界上90%的数据就产生了。
我们以各种形式与互联网互动的次数越多?– 从发送短信、分享视频或创作音乐?,我们为支持生成人工智能 (GenAI) 技术的训练数据池做出了贡献。
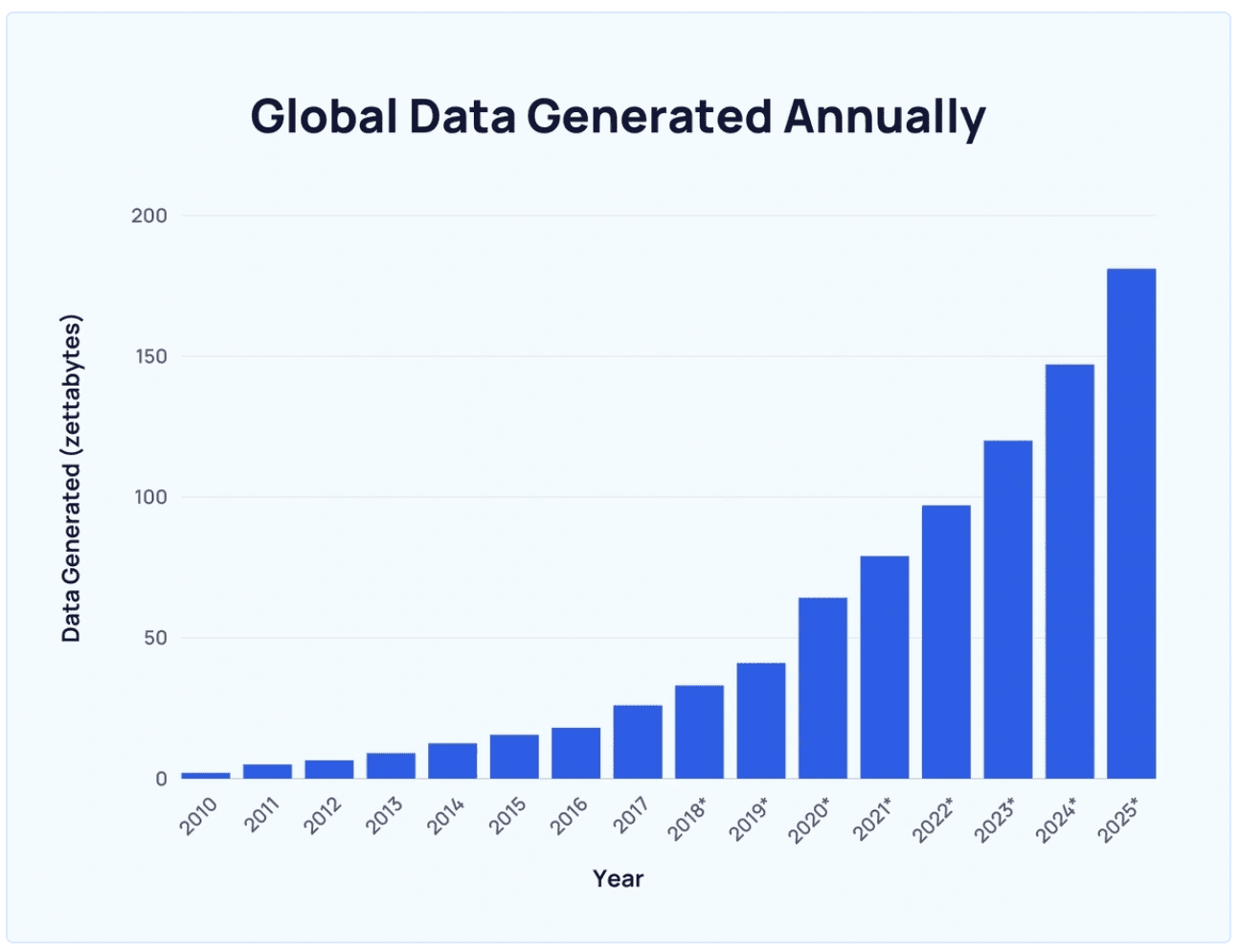
每年从 explodingtopics.com 生成的全球数据
原则上,我们的数据作为这些高级AI算法的输入,这些算法可以学习和生成更新的数据。
GenAI的另一面
不用说,起初这听起来很有趣,但随着现实开始出现,它开始以各种形式构成风险。
这些技术发展的另一面很快打开了潘多拉的问题盒子?以错误信息、滥用、信息危害、深度伪造、碳排放等形式出现。
此外,重要的是要注意这些模型在使许多工作变得多余方面的影响。
根据麦肯锡最近的报告“生成人工智能和美国工作的未来”?—?涉及大量重复性任务、数据收集和基本数据处理的工作被淘汰的风险增加。
该报告引用了包括GenAI在内的自动化,这是对基本认知和手工技能需求下降的原因之一。
此外,从前GenAI时代一直存在并继续构成挑战的一个重要问题是数据隐私。构成GenAI模型核心的数据是从互联网上策划的,其中包括我们身份的一小部分。

据称,其中一个LLM接受了大约300亿个单词的训练,这些数据是从互联网上抓取的,包括书籍,文章,网站和帖子。令人担忧的是,我们一直不知道它的收集、消费和使用。
《麻省理工学院技术评论》发现,“OpenAI几乎不可能遵守数据保护规则”。
开源是解决方案吗?
由于我们所有人都是这些数据的部分贡献者,因此期望开源算法并使其对每个人都透明。
虽然开放获取模型提供了有关代码、训练数据、模型权重、架构和评估结果的详细信息?—?但基本上是你需要知道的一切。

图片来自 Canva
但是我们大多数人都能理解它吗?应该不会!
这就需要在适当的论坛上分享这些重要细节——一个由专家组成的委员会,包括政策制定者、从业者和政府。
这个委员会将能够决定什么对人类最有利?—?这是今天没有一个单独的团体、政府或组织可以自己决定的。
它必须将对社会的影响视为高度优先事项,并从社会、经济、政治等不同角度评估 GenAI 的影响?—?。
治理不妨碍创新
撇开数据组件不谈,这种巨大模型的开发人员进行了大量投资,以提供构建这些模型的计算能力,从而使他们有权保持封闭访问。
进行投资的本质意味着他们希望通过将此类投资用于商业用途来获得回报。这就是混乱开始的地方。
拥有一个能够监管人工智能应用程序开发和发布的管理机构不会抑制创新或阻碍业务增长。
相反,其主要目标是建立护栏和政策,通过技术促进业务增长,同时促进更负责任的方法。
那么,谁来决定责任商数,这个管理机构又是如何形成的呢?
需要一个负责任的论坛
应该有一个由来自研究、学术界、企业、政策制定者和政府/国家的专家组成的独立实体。澄清一下,独立意味着其资金不得由任何可能导致利益冲突的玩家赞助。
它的唯一议程是代表这个世界上8亿人思考,合理化和行动,并做出合理的判断,对其决策保持高问责标准。
现在,这是一个重要的声明,这意味着,团队必须专注于激光,并将委托给他们的任务视为次要任务。我们世界不能让决策者从事诸如“可有可无”或副项目这样一项关键任务,这也意味着他们也必须得到良好的资助。
该小组的任务是执行一项计划和战略,该计划和战略可以在不影响实现技术收益的情况下解决危害。
我们以前做过
人工智能经常被比作核技术。其尖端发展使得很难预测随之而来的风险。
引用《连线》杂志的鲁曼的话,国际原子能机构(IAEA)?—?一个没有政府和公司隶属关系的独立机构是如何成立的,为核技术的深远影响和看似无限的能力提供解决方案。
因此,我们过去有全球合作的例子,世界走到一起,将混乱整顿起来。我确信我们会在某个时候到达那里。但是,至关重要的是,要尽快融合并形成护栏,以跟上快速发展的部署步伐。
人类不能把自己放在企业的自愿措施上,希望科技公司负责任地开发和部署。
由3D建模学习工作室 整理翻译,转载请注明出处!