合成数据如何解决人工智能偏见问题?
纵观历史,人类一直存在偏见和歧视。我们的行为似乎不会很快消失。偏见出现在程序和算法中,与人类不同,它们似乎对这个问题免疫。

机器学习训练模型推荐:UnrealSynth虚幻合成数据生成器
在解释如何使用合成数据生成来解决 AI 偏见及其分类之前,我们需要了解它是如何形成的。随着人工智能的进步,关于数据科学解决方案的问题和道德困境开始出现。由于人类已经远离决策过程,他们需要确定这些系统做出的决定绝不是偏见或歧视性的。人工智能必须受到监督。
由于人工智能通常代表一个基于预测分析的数字系统,该系统在大数据上运行,我们不能说是人工智能产生了潜在的偏见。问题开始得更早,实际的无监督数据被“馈送”到系统中。
纵观历史,人类一直存在偏见和歧视。我们的行为似乎不会很快消失。偏见出现在程序和算法中,与人类不同,它们似乎对这个问题免疫。
什么是人工智能偏见?
在与数据相关的行业中,当您的员工以样本不能准确代表您感兴趣的人群的方式收集数据时,就会发生偏差。您将能够找到许多类似的定义,这些定义通常讲述相同的故事。在实践中,这意味着特定背景、宗教、肤色和性别的人在数据样本中的代表性不足。这可能会导致您的系统做出歧视性决策。它还提出了一些问题,例如什么是数据科学咨询以及它是否重要。

人工智能中的偏见并不意味着你设计的人工智能系统故意偏向于某些人群。人工智能的目的是让人们使用示例而不是指令来解释他们想要什么。所以,如果AI有偏见,它只能由于有偏见的数据而发生!人工智能决策是在现实世界中工作的理想化过程,它无法掩盖人类的缺点。包括监督学习也是有益的。
“偏见不是来自人工智能算法;它来自人。
它是如何发生的?
正如我们已经提到的,偏差问题的出现是因为数据可以包括基于刻板印象的人类决策,适合积极的算法结果。那么如何训练这些算法呢?
例子
现实生活中存在许多人工智能偏见的例子。谷歌的仇恨言论检测算法歧视有色人种和已知的变装皇后。十年来,亚马逊的人力资源算法主要由男性员工数据提供,这后来导致女性候选人更有可能被认为适合在亚马逊工作。
麻省理工学院的数据科学家发现,面部识别算法在分析少数族裔(尤其是少数族裔女性)的面孔时具有更高的错误率,这可能是由于在算法训练期间主要以白人男性面孔为食。看看下面的实际结果。即使没有新形成的戴口罩进行面部识别的问题,算法也已经难以识别特定人群或任何非白人男性的面孔。

问题很明显,需要以某种方式解决。如果这样的问题发生在大数据公司身上,那么与神经网络、数据科学和人工智能相关的所有领域的领导者,都会想象其他更小的学习模型。机器的合成数据代表了潜在的进步,所以让我们看看它到底是怎么回事。
什么是合成数据及其生成方式?
合成数据是部分或完全人工生成的数据,而不是从现实世界的事件或现象中测量或提取的数据。尽管是人为的,但它可以帮助处理很多场景,例如:
- 真实数据稀缺且不足
- 新数据挖掘困难或昂贵
- 实际数据对某些人群有偏见和不公平
您可以通过三种方式生成它:
- 完全合成:所有数据均由计算机生成
- 部分合成:您可以将真实数据替换为生成的数据
- 更正:修改真实数据以适应特定要求
合成数据生成的方法可以使用深度学习模型、机器学习、数据科学方法或任何可用的商业合成数据生成工具。是的,在一些合成数据公司,数据科学家共同为需要它的各种企业生成合成数据。
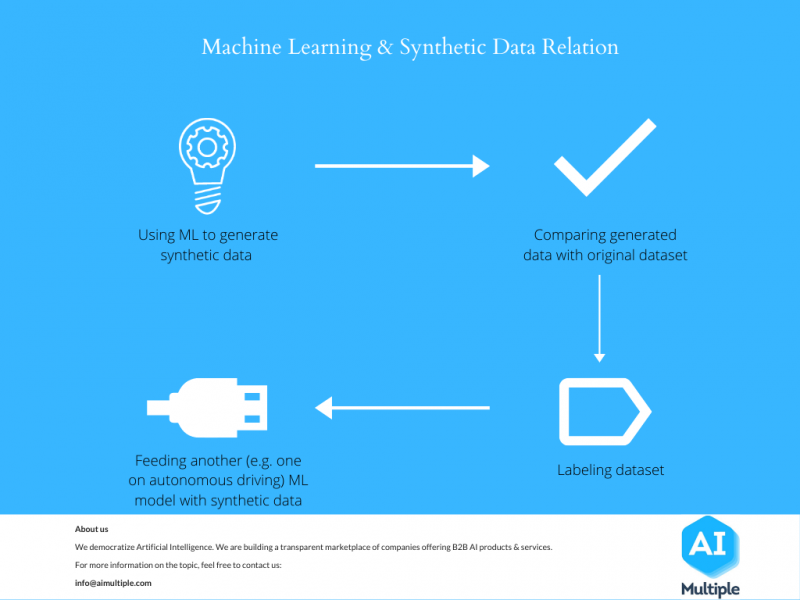
很明显,合成 AI 数据生成如何通过生成人工数据或在原始数据进入 AI 或机器学习算法之前对其进行修改来帮助减少 AI 偏见。
合成数据如何解决人工智能偏见问题?
一个理想的世界不应该包含偏见,无论种族、性别、宗教或性取向如何,人们都会有平等的机会。然而,现实世界中充满了这种情况——在特定领域偏离大多数人的人在找工作和接受教育方面有更多的问题,这使得他们在许多数据集中的代表性不足。
这可能会导致错误的结论,即这些人的能力较差,不太适合出现在这些数据集中,也不太适合获得正分,这取决于人工智能系统的目的。
“[机器学习算法]尚未针对任何公平性定义进行优化,”加州大学伯克利分校信息学院副教授Deirdre Mulligan说。“他们已经过优化,可以完成一项任务。”
然而,合成 AI 数据可以代表着朝着无偏见 AI 的方向迈出了一大步。以下是其背后的一些想法:
- 我们可以分析真实世界的数据并观察偏差。然后,我们可以根据真实世界的数据和观察到的偏差生成数据。如果你想要一个完美的虚拟数据生成器,你需要提供一个公平性定义,试图将数据(有偏见的)转换为可以被认为是公平的东西。
- 如果数据集不够多样化或不够大,人工智能生成的数据可以填补漏洞并形成一个无偏见的数据集。即使您的样本量很大,与其他人相比,某些人也可能被排除在外或代表性不平等。合成数据需要能够解决此问题。
生成无偏见的数据可能比昂贵的数据挖掘更容易。收集实际数据需要测量、访谈、大样本量,而且在任何情况下都需要大量的工作。人工智能生成的数据很便宜,而且只需要数据科学/机器学习技术。
人脸识别
我们以面部识别为例。“如果训练集不是那么多样化,任何偏离既定规范的面孔都将更难被发现,这就是发生在我身上的事情,”麻省理工学院研究员乔伊·布兰维尼说。“训练集不是凭空出现的。我们可以创造它们。因此,我们有机会创建全方位的训练集,以反映更丰富的人性画像。

向 AI 算法提供由 80% 的高加索人脸和 20% 属于有色人种的面孔组成的面部数据,可以合理地预测该算法在白人的面部上表现更好。
但是,如果您生成足够多的合成 AI 数据来代表有色人种的人造面孔,并将其与白人面孔一起提供给 AI 算法,则可以预期所有种族的错误率都相同。因此,如果您考虑开发人脸检测程序,请确保无论此人的种族或性别如何,它都能正常工作。
此外,生成合成人脸具有不带任何隐私问题的优势。在人工智能和数据隐私之间的相关性与许多互联网用户有关的时代,生成自己的合成数据(在这种情况下是人脸)是一个更安全的选择。
最后的话
人工智能偏见是一个真正的问题,它可以以各种方式影响人们。他们可能不会收到面试邀请,银行会拒绝他们的贷款申请,甚至成为法律力量监视的候选人。风险很高,人工智能的全部意义在于消除人类犯的主观错误。
然而,有偏见的不是算法:而是我们的数据!人为因素可能很难减少,如果我们觉得有必要从我们的人工智能系统中消除它,我们就需要在数据进入算法之前消除数据中的偏见。建议的解决方案是合成数据生成。
生成的合成数据可以是完整的,也可以是部分的。这是一种独特的方式,可以确保我们平等对待每个人,并且每个人的“权重系数”都是相同的。该算法认为,如果男性在过去十年中担任特定角色,则意味着男性更擅长。它不知道现实世界的残酷和严酷的现实。在计算机科学世界中,从算法中消除这种推理是很困难的,但如果我们想向一个更加平等和公正的社会迈出一步,这是必须的。