如何从大型语言模型获得更好的输出
在接受过大量文本语料库的培训后,LLM可以在没有太多指导或培训的情况下为各种应用程序操作和生成文本。但是,此生成的输出的质量在很大程度上取决于您为模型提供的指令,这称为提示。这对你意味着什么?如今,与模型交互是设计提示的艺术,而不是设计模型体系结构或训练数据。

在线工具推荐:三维数字孪生场景工具 - GLTF/GLB在线编辑器 - Three.js AI自动纹理化开发 - YOLO 虚幻合成数据生成器 - 3D模型在线转换 - 3D模型预览图生成服务
如何从大型语言模型获得更好的输出

大型语言模型(LLM)因其以前所未有的规模理解和处理人类语言的能力而在全球范围内引起了轰动。它改变了我们与技术互动的方式。
在接受过大量文本语料库的培训后,LLM可以在没有太多指导或培训的情况下为各种应用程序操作和生成文本。但是,此生成的输出的质量在很大程度上取决于您为模型提供的指令,这称为提示。这对你意味着什么?如今,与模型交互是设计提示的艺术,而不是设计模型体系结构或训练数据。
考虑到构建和训练模型所需的专业知识和资源,处理LLM可能会付出代价。NVIDIA NeMo 提供预训练的语言模型,可以灵活地适应解决几乎任何语言处理任务,同时我们可以完全专注于从可用 LLM 获得最佳输出的艺术。
在这篇文章中,我讨论了一些使用LLM的方法,以便您可以充分利用它们。有关 LLM 入门的详细信息,请参阅大型语言模型简介:提示工程和 P 调优。
提示背后的机制
在我进入生成最佳输出的策略之前,请退后一步,了解提示模型时会发生什么。提示被分解为称为令牌的较小块,并作为输入发送到LLM,然后LLM根据提示生成下一个可能的令牌。
标记化
LLM 将文本数据解释为标记。标记是单词或字符块。例如,单词“sandwich”将被分解为令牌“sand”和“wich”,而“time”和“like”等常用词将是一个标记。
NeMo 使用字节对编码来创建这些令牌。提示被分解为由LLM作为输入的令牌列表。
代
在幕后,模型首先为每个可能的输出令牌生成对数。Logits 是一个函数,表示从 0 到 1 以及负无穷大到无穷大的概率值。然后将这些对数传递给 softmax 函数,为每个可能的输出生成概率,从而为您提供词汇表的概率分布。以下是用于计算代币实际概率的softmax方程:

在公式中,

是给定上下文的概率,来自先前标记(

和

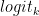
是神经网络的
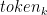
输出
然后,模型将选择最可能的单词并将其添加到提示序列中。

当模型决定最可能的输出时,您可以通过上下转动某些模型参数旋钮来影响这些概率。在下一节中,我将讨论这些参数是什么以及如何调整它们以获得最佳输出。
调整参数
为了释放LLM的全部潜力,探索完善产出的艺术。以下是要考虑调整的关键参数类别:
- 让模型知道何时停止
- 可预测性与创造力
- 减少重复
尝试使用这些参数,找出适合您的特定用例的最佳组合。在许多情况下,试验温度参数可以得到您可能需要的东西。但是,如果您有特定的东西并希望对输出进行更精细的控制,请开始尝试其他输出。
让模型知道何时停止
有一些参数可以指导模型决定何时停止生成任何进一步的文本:
- 代币数量
- 停用词
代币数量
之前,我提到LLM专注于在给定令牌序列的情况下生成下一个令牌。模型在循环中执行此操作,将预测的令牌追加到输入序列。你不会希望LLM继续下去。
虽然 NeMo 模型目前可以接受的代币数量从 2048 到 4096 不等,但我不建议达到这些限制,因为模型可能会生成响应。
停用词
停用词是一组字符序列,它告诉模型停止生成任何其他文本,即使输出长度未达到指定的标记限制也是如此。
这是控制输出长度的另一种方法。例如,如果系统提示模型完成以下句子“天空是蓝色的,柠檬是黄色的,酸橙是”,并且您将停用词指定为“.”,则模型在完成此句子后停止,即使标记限制高于生成的序列(图 2)。
在几次拍摄设置中设计停止模板特别有用,这样模型就可以学会在完成预期任务时适当地停止。图 3 显示了使用字符串“===”分隔示例并将其作为停用词传递。
可预测性与创造力
给定提示,可以根据您设置的参数生成不同的输出。根据LLM的应用,您可以选择增加或减少模型的创造能力。以下是可以帮助您执行此操作的一些参数:
- 温度
- Top-k 和 Top-p
- 光束搜索宽度
温度
此参数控制模型的创作能力。如前所述,在生成输入序列中的下一个令牌时,模型会得出概率分布。温度参数可调整此分布的形状,从而使生成的文本更加多样化。
在较低的温度下,模型更加保守,仅限于选择概率较高的代币。随着温度的升高,该限制会变得宽松,允许模型选择可能性较小的单词,从而产生更多不可预测和创造性的文本。
图 4 显示了让模型完成以“海洋”开头的句子的任务,其中将温度设置为 0.1。
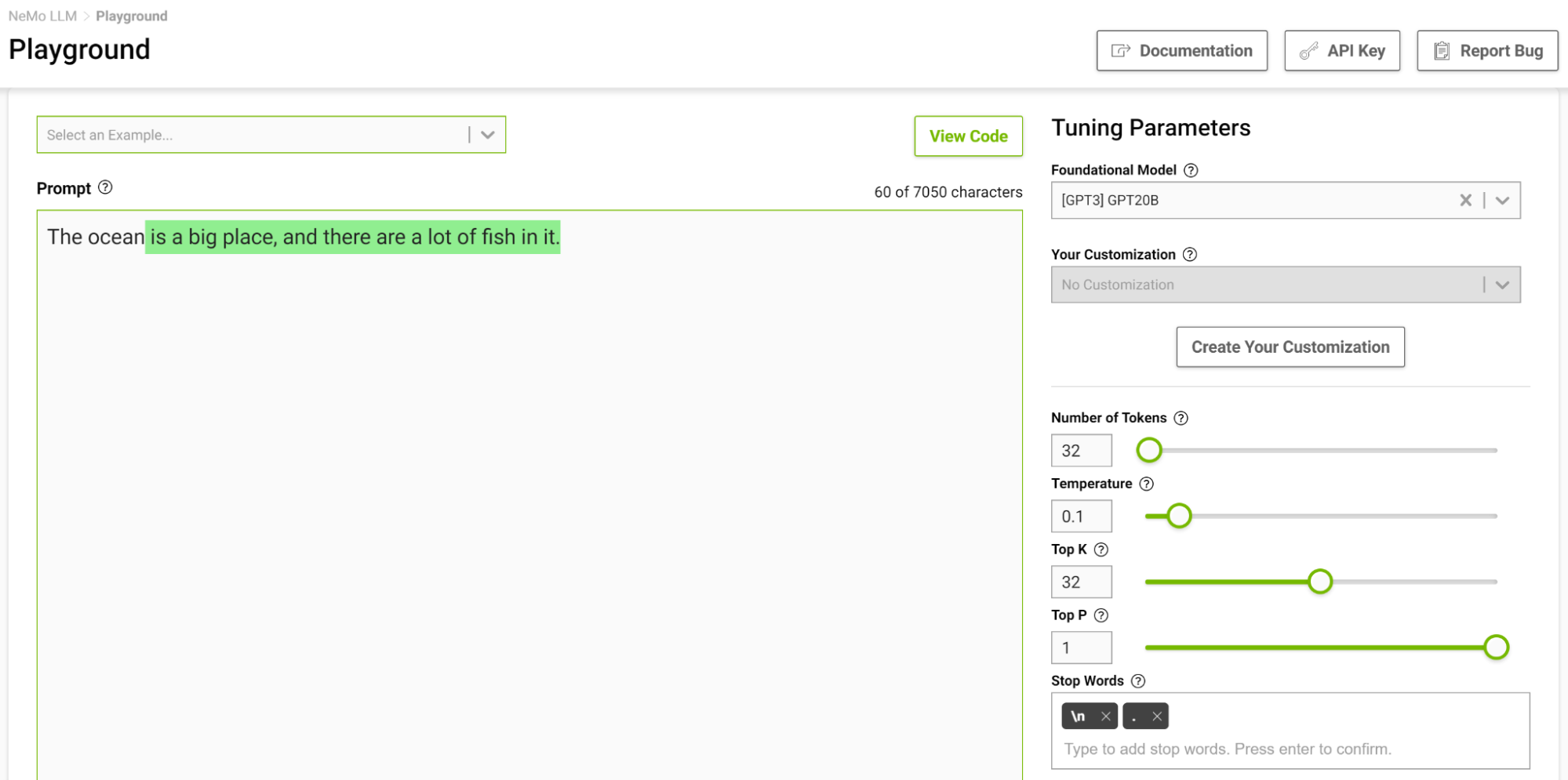
当您想到完成这样的短语时,您可能会想到诸如“......是巨大的“或”...是蓝色的”。输出几乎是一个简单的事实,海洋很大,有很多鱼。
现在,使用温度设置为 1 再次尝试此操作(图 5)。
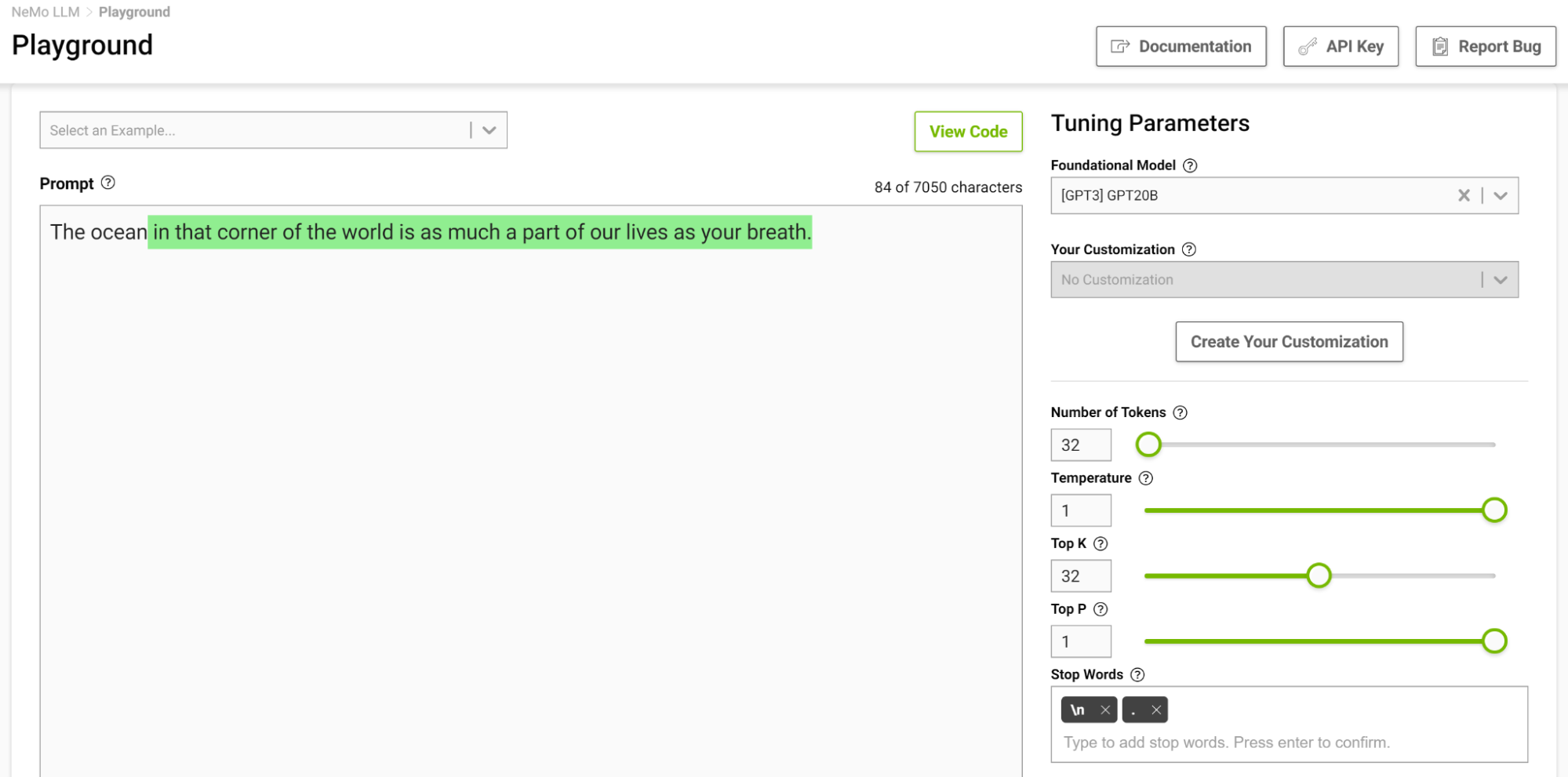
这个模型开始给你一个你通常不会想到的类比。较高的温度适合需要创造性写作的任务,如诗歌和故事。但请注意,生成的文本有时也会变得无意义。较低的温度适用于更明确的任务,如问答或总结。
我建议尝试不同的温度值,以找到适合您的用例的最佳温度。该范围应该是NeMo服务游乐场的良好起点。[0.5, 0.8]
Top-k 和 Top-p
这两个参数还控制选择下一个令牌的随机性。Top-k 告诉模型它必须保留前 k 个最高概率的令牌,从中随机选择下一个令牌。较低的值会降低随机性,因为您正在剪掉不太可能生成可预测文本的标记。如果 k 设置为 0,则不使用 Top-k。当设置为 1 时,它始终会选择下一个最可能的令牌。
在某些情况下,可能的代币的概率分布可能很宽,因为可能有这么多的代币。也可能存在分布狭窄的情况,只有少数代币更有可能。
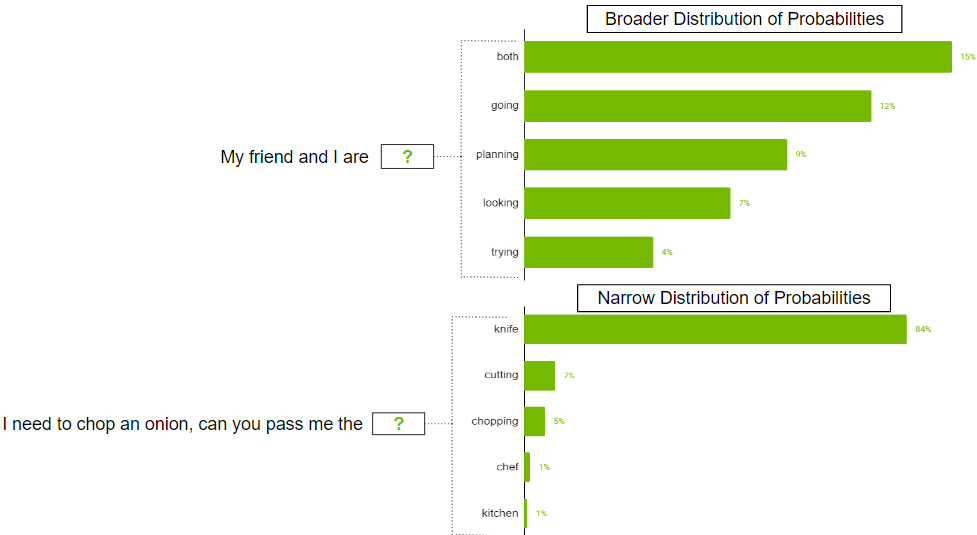
你可能不希望严格限制模型,使其只选择更广泛的分发方案中的前 k 个令牌。为了解决这个问题,可以使用参数 top-p,其中模型从概率总和等于或超过 top-p 值的最高概率令牌中随机选择。如果 top-p 设置为 0.9,则可能会出现以下情况之一:
- 在更广泛的分布示例中,它可以考虑概率总和等于或超过 50.0 的前 9 个代币。
- 在窄分布方案中,仅使用前两个令牌即可超过 0.9。这样,您可以避免从随机代币中挑选,同时仍保留品种。
光束搜索宽度
这是另一个有用的参数,可以控制输出的多样性。波束搜索是许多NLP和语音识别模型中常用的算法,作为在给定可能选项的情况下选择最佳输出的最后决策步骤。波束搜索宽度是一个参数,用于确定算法在搜索的每个步骤中应考虑的候选数量。
较高的值会增加找到良好输出的机会,但这也以更多计算为代价。
减少重复
有时,输出中可能不需要重复的文本。如果是这种情况,请使用重复惩罚参数来帮助减少重复。
重复处罚
此参数可以帮助根据标记在文本中出现的频率(包括输入提示)来惩罚标记。已经出现五次的令牌比只出现一次的令牌受到的惩罚更严重。值为 1 表示没有惩罚,大于 1 的值不鼓励重复令牌。
有效提示设计的少镜头策略
及时的设计对于从LLM产生相关和连贯的产出至关重要。制定有效的提示设计策略可以帮助创建相关的提示,同时避免偏见、歧义或缺乏特异性等常见陷阱。在本节中,我将分享一些有效提示设计的关键策略。
提示约束
通过仔细的提示设计来约束模型的行为可能非常有用。你知道,语言模型的核心是试图预测序列中的下一个单词。对人类完全有意义的任务描述可能无法被语言模型理解。这就是为什么少镜头学习通常效果很好:当你向模型展示一个模式时,它会很好地坚持它。
请考虑以下提示,“将英语翻译成法语:今天是美好的一天。
使用此提示,模型可能会尝试继续句子或添加更多句子,而不是执行翻译。将提示更改为“将此英语句子翻译成法语:今天是美好的一天”,增加了模型将此任务理解为翻译任务并生成更可靠输出的可能性。
角色很重要!
正如您在前面的翻译示例中所看到的,微小的更改可能会导致不同的输出。需要注意的另一件事是,标记通常是使用前导空格生成的,因此空格和下一行等字符也会影响您的输出。如果提示不起作用,请尝试更改其结构化方式。
考虑某些短语
通常,当您希望模型合乎逻辑地回答提示并得出准确的结论或只是为了使模型达到特定结果时,可以考虑使用以下短语:
- 让我们一步一步地思考一下:这鼓励模型从逻辑上处理问题并得出准确的答案。这种提示方式也称为思维链促进 (CoT)。
- 以<著名人物>的风格:这与著名人物的写作风格相匹配。例如,要生成莎士比亚或埃德加·爱伦·坡等文本,请将其添加到提示中,生成将紧密匹配他们的写作风格。
- 作为<职业/角色>:这有助于模型更好地理解问题的上下文。有了更好的理解,模型通常会给出更好的答案。
提示生成的知识
为了获得更准确的答案,您可以提示LLM在生成最终答案之前生成有关给定问题的潜在有用知识(图7)。

这种类型的错误表明LLM有时需要更多的知识来回答问题。接下来的示例显示了在几次击球设置中生成有关高尔夫得分的一些事实。
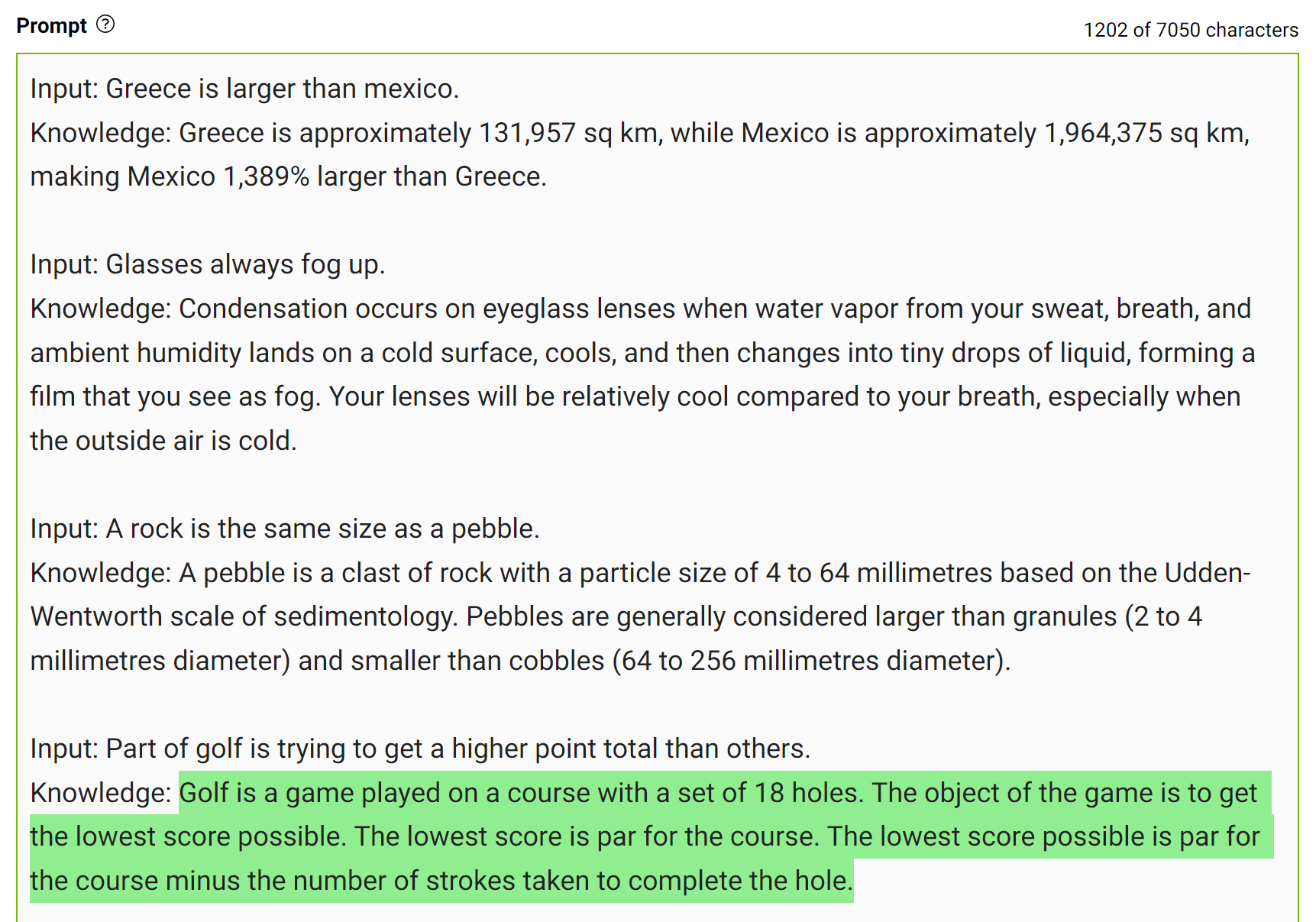
将此知识整合到提示中,然后再次提问。
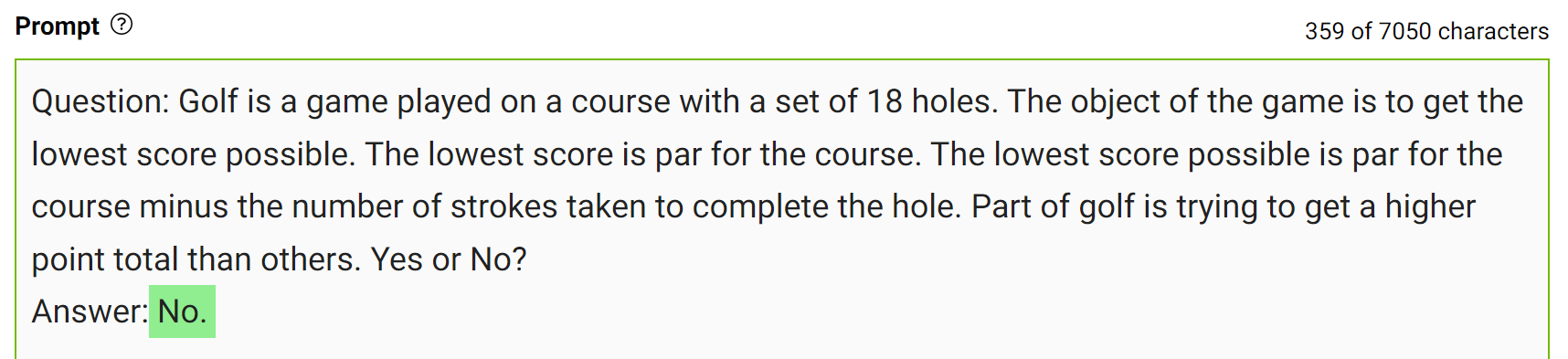
该模型自信地对同一问题回答“否”。这是这种提示的简单演示。但是,在得出最终答案之前,还需要考虑更多细节。
3D建模学习工作室 翻译整理,转载请注明出处!