用于地理空间数据分析的 5 个 Python 包
推荐:使用NSDT编辑器快速搭建3D应用场景

推荐:使用NSDT编辑器快速搭建3D应用场景
在当今世界快速发展的格局中,数据正在经历指数级增长,计算需求正在飙升,传统的信息处理方法往往是不够的。这就是分布式处理发挥作用的地方。
分布式处理是指将复杂任务分解为更小的、可管理的部分,并在多台机器或计算资源上同时执行它们的过程。通过利用这些资源的集体力量,分布式处理使我们能够高效且有效地处理大规模计算。
训练机器学习 (ML) 模型对计算能力的需求一直在迅速增加。自 2010 年以来,对计算的需求每 18 个月增长十倍。然而,GPU和TPU等AI加速器的功能并没有跟上这种需求,因为它们在同一时期只翻了一番。
因此,组织现在每年半需要五倍多的 AI 加速器或节点来训练最新的 ML 模型并利用最新的 ML 功能。为了满足这些要求,分布式计算是唯一的解决方案。
本教程介绍了 Ray,这是一个简化分布式计算的开源 Python 框架。
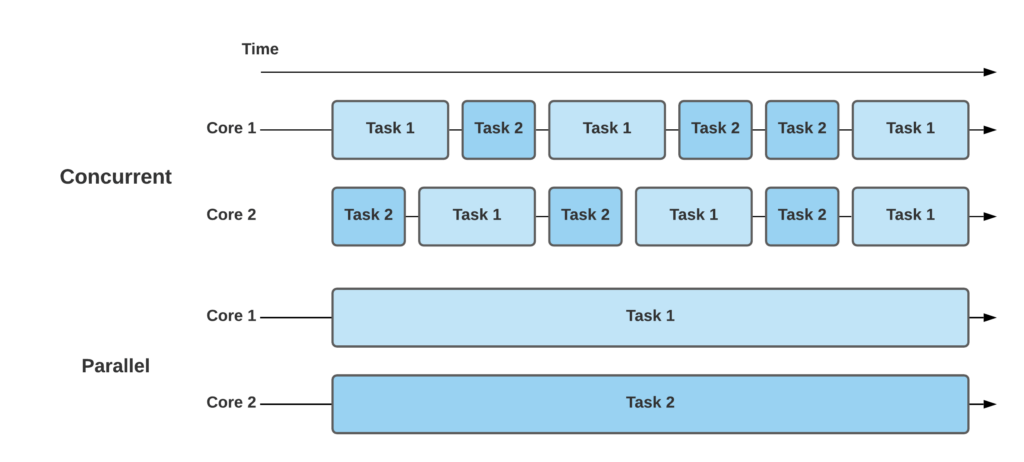
什么是雷?
Ray是一个开源框架,旨在支持在Python中开发可扩展和分布式应用程序。它为构建分布式系统提供了一种简单灵活的编程模型,从而更容易利用并行和分布式计算的强大功能。Ray 框架的一些关键特性和功能包括:
任务并行性
Ray 允许您通过跨多个 CPU 内核甚至跨计算机集群并发执行任务来轻松并行化 Python 代码。这样可以加快计算密集型任务的执行速度并提高性能。
分布式计算
Ray 提供分布式执行模型,允许您将应用程序扩展到单台机器之外。它提供了用于分布式调度、容错和资源管理的工具,使处理大规模计算变得更加容易。
远程函数执行
使用 Ray,您可以定义可以远程执行的 Python 函数。这使您能够将计算卸载到集群中的不同节点,从而分配工作负载并提高整体效率。
分布式数据处理
Ray 为分布式数据处理提供了高级抽象,例如分布式数据帧和分布式对象存储。通过这些功能,可以更轻松地处理大型数据集,并以分布式方式执行筛选、聚合和转换等操作。
强化学习支持
Ray 包括对强化学习算法和分布式训练的内置支持。它为训练和评估机器学习模型提供了可扩展的执行环境,从而实现高效的实验和更快的训练时间。
Ray 框架概述
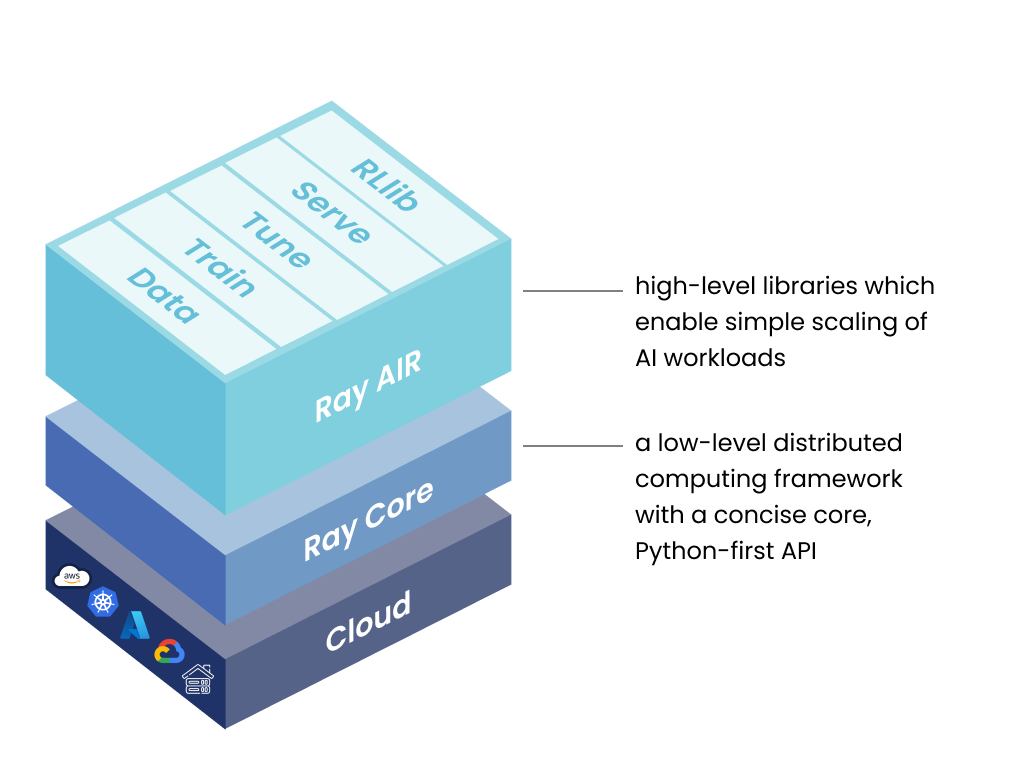
Ray 的框架包含三层:
1. 射线 AI 运行时 (AIR)
这个开源的 Python 库集合专为 ML 工程师、数据科学家和研究人员设计。它为他们提供了一个统一且可扩展的工具包,用于开发 ML 应用程序。Ray AI 运行时由 5 个核心库组成:
射线数据
无论底层框架如何,都可以跨各个阶段(例如训练、调优和预测)实现数据加载和转换的可扩展性和灵活性。
雷火车
支持跨多个节点和内核的分布式模型训练,结合容错机制,与广泛使用的训练库无缝集成。
雷调
扩展超参数优化过程以提高模型性能,确保发现最佳配置。
雷发球
借助 Ray 可扩展和可编程的服务功能,轻松部署模型以进行在线推理。(可选)利用微批处理来进一步提高性能。
雷·
将可扩展的分布式强化学习工作负载与其他 Ray AIR 库无缝集成,从而高效执行强化学习任务。
2. 射线核心
这个开源的 Python 库用作通用的分布式计算解决方案。它使 ML 工程师和 Python 开发人员能够扩展 Python 应用程序并加速机器学习工作负载的执行。
射线核心的关键概念
任务
Ray 允许你在单独的 Python worker 上独立运行函数。这些函数称为“任务”,可以异步执行。Ray 允许您指定每个任务所需的资源(例如 CPU、GPU 和自定义资源)。然后,群集计划程序在群集中分配任务以并行运行它们。
演员
Actor是Ray的API的扩展,它超越了函数(任务)来处理类。参与者就像一个持有状态或充当服务的工人。创建新参与者时,将为其分配一名专用工作人员。参与者的方法计划在该特定工作线程上,并且可以访问和更改其状态。与任务类似,参与者也可以具有资源要求,例如 CPU、GPU 和自定义资源。
对象
在 Ray 中,任务和 actor 对对象进行操作。这些对象被称为远程对象,因为它们可以存储在 Ray 集群中的任何位置。我们使用对象引用(对象引用)来引用这些远程对象。Ray 的分布式共享内存对象存储缓存这些远程对象,集群中的每个节点都有自己的对象存储。在群集中,远程对象可以存在于一个或多个节点上,无论哪个节点保存对象引用。
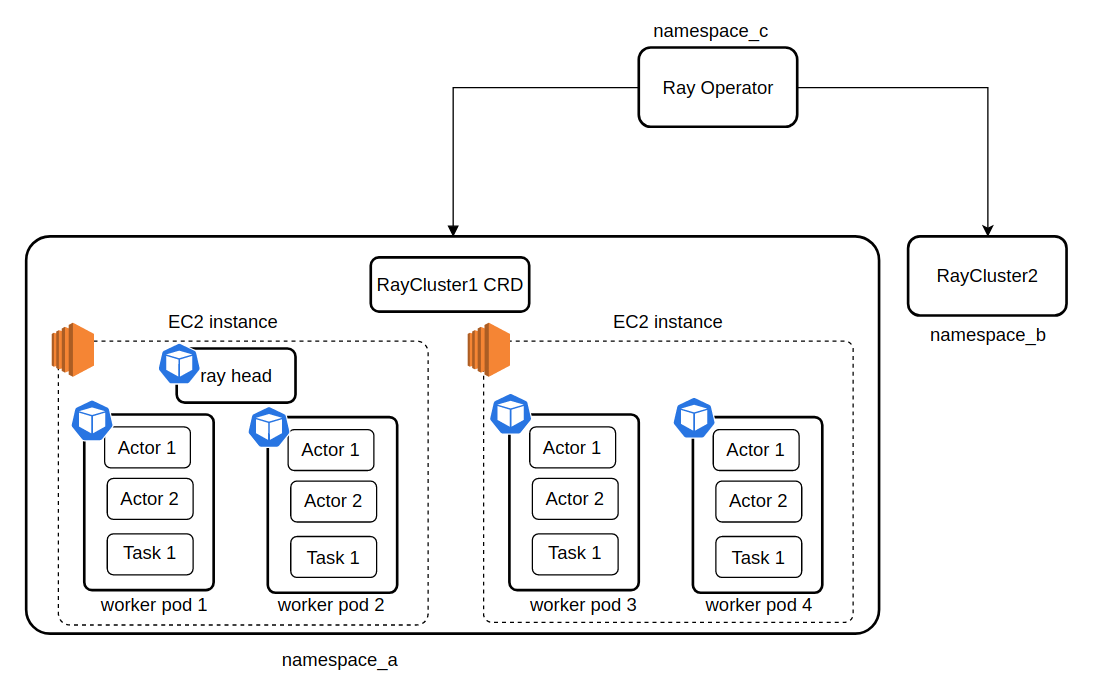
3. 射线簇
Ray 集群由一组连接到中央 Ray 头节点的工作节点组成。这些群集可以配置为固定大小,也可以根据群集上运行的应用程序的资源要求动态自动缩放。
射线集群中的关键概念
具有两个工作器节点的 Ray 集群。
簇
Ray 集群由链接到中央 Ray 头节点的工作器节点集合组成。这些群集可以具有预定义的大小,也可以根据群集中运行的应用程序的资源要求动态扩展或缩减。
头节点
在每个 Ray 群集中,都有一个指定的头节点负责群集管理任务,例如运行自动缩放程序和 Ray 驱动程序进程。尽管头节点充当常规工作节点,但它也可能被分配任务和执行组件,这对于大规模群集来说并不理想。
工作节点
Ray 集群中的工作节点全权负责执行 Ray 任务和 actor 中的用户代码。它们不参与运行任何头节点管理进程。这些工作节点在分布式调度中起着至关重要的作用,并负责在整个集群内存中存储和分发 Ray 对象。
自动缩放
在头节点上运行的 Ray 自动缩放程序根据 Ray 工作负载的资源要求调整群集大小。当工作负载超过群集的容量时,自动缩放程序会尝试添加更多工作器节点。相反,它会从群集中删除空闲的工作器节点。请务必注意,自动缩放程序专门响应任务和执行组件资源请求,不考虑应用程序指标或物理资源利用率。
雷·乔布斯
Ray 作业是指由一组派生自通用脚本的 Ray 任务、对象和 actor 组成的单个应用程序。负责执行 Python 脚本的工作线程称为作业的驱动程序。
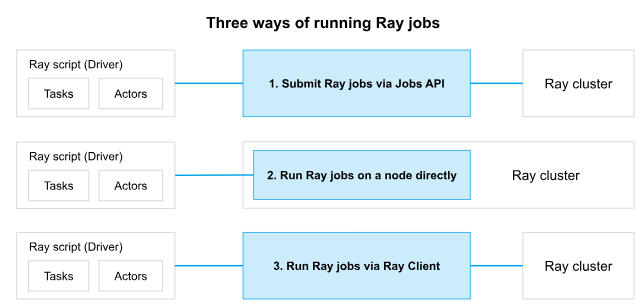
在 Ray 集群上运行作业的三种方式。
射线安装和设置
您可以从 PyPI 安装最新的正式版 Ray。如果你想主要为机器学习应用程序安装 Ray,你很可能需要 ray[air]。pip install ray[air] OpenAI
对于一般的 Python 应用程序:pip install ray[default] OpenAI
雷和查特

OpenAI的ChatGPT由Ray平台提供支持,受益于并行模型训练。这意味着多台计算机不是只使用一台计算机,而是协同工作来训练模型。这允许 ChatGPT 在比它自己处理的更大的数据集上进行训练。
在训练像 ChatGPT 这样的语言模型时,它涉及分析大量文本数据并调整模型的设置以改进其预测。此过程可能是计算密集型且耗时的,尤其是在处理大量数据集时。
在 ChatGPT 的训练期间,Ray 的分布式数据结构和优化器在管理和处理大量数据方面发挥了至关重要的作用。
一个简单的 Python 示例:在远程集群上运行 Ray 任务
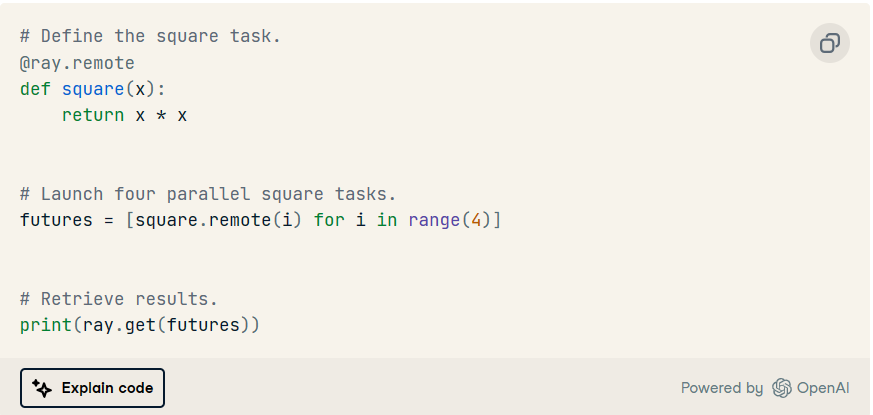
使用 Ray,您可以将函数作为远程任务在集群上运行。要使用 Ray,您需要将装饰器添加到要远程运行的函数中。不是直接调用函数,而是在函数名称后使用。此远程调用为您提供了一个 future 对象,它类似于对函数结果的引用。您可以通过在将来对象上使用来检索实际结果。@ray.remote.remote()ray.get
使用射线对scikit学习模型进行并行超参数调优
以下代码使用 Ray 库进行并行处理,对支持向量机 (SVM) 模型进行超参数优化的随机搜索。它首先导入必要的库并从 加载手写数字数据集。scikit-learn
超参数的搜索空间在名为 的字典中定义。使用该模块创建具有径向基函数内核的 SVM 模型,并使用模型和搜索空间实例化对象。param_spacesklearn.svmRandomizedSearchCV
然后,代码将 Ray 设置为并行处理,并使用该方法执行超参数搜索。通过利用 Ray 的并行处理功能,代码加快了搜索过程,探索各种超参数组合,以找到 SVM 模型的最佳配置。
代码运行时的日志:

结论
在这篇博客中,我们探讨了使用 Python 中的 Ray 框架进行分布式处理的强大功能。Ray 为并行化 AI 和 Python 应用程序提供了一种简单灵活的解决方案,使我们能够利用多台机器或计算资源的集体力量。我们讨论了 Ray 框架的主要特性和功能,包括任务并行性、分布式计算、远程函数执行和分布式数据处理。
由3D建模学习工作室 整理翻译,转载请注明出处!