数据可视化:理论与技术
良好的数据可视化不仅仅是呈现数字,而是试图围绕故事阐明我们的数据。在讲故事的同时使我们的数据栩栩如生,并在原始信息与现实世界的影响和见解之间建立联系。

推荐:使用NSDT场景编辑器快速搭建3D应用场景
在由大数据和复杂算法主导的数字环境中,人们会认为普通人迷失在数字和数据的海洋中。
不是吗?
然而,原始数据和可理解的见解之间的桥梁在于数据可视化的艺术。
它是指引我们的指南针,是指导我们的地图,是解码我们每天遇到的大量数据的解释器。
但是,良好的可视化背后的魔力是什么?
为什么一个可视化会启发而另一个可视化会令人困惑?
今天,我们将回到基础,并尝试了解数据可视化的基础知识。
让我们一起来探索吧!👇🏻
打破数据可视化的基础
掌握如何有效地讲故事是数据科学家最难掌握的技能之一。如果我们在字典中检查术语数据可视化,我们会发现以下定义:
“将信息表示为图片、图表或图表,或以这种方式表示信息的图片的行为”
这基本上意味着数据可视化旨在从数据集中制作一个故事,以易于理解、吸引人和有影响力的形式呈现见解。
数据可视化,或者让数据在图表和图形中看起来不错,可能看起来不像机器学习之类的东西那么酷。
但是,这确实是数据科学家工作的关键部分。
在当今数据驱动的世界中,数据可视化就像帮助我们看清事物的眼镜。而且,对于那些不精通数字和算法语言的人来说,它提供了一种理解复杂数据叙述的有效方法。
任何图表始终由两个主要组件组成:
1. 数据类型
我敢打赌,您将数据视为数字,但数值只是我们可能遇到的几种数据类型中的两种。每当我们可视化数据时,我们总是需要考虑我们正在处理的数据类型。
除了连续和离散数值之外,数据还可以以离散类别的形式、日期或时间的形式以及文本的形式出现。
当数据是数字时,我们也称之为定量,当它是分类的时,我们称之为定性。
因此,任何显示的数据始终可以在以下类别之一中描述。
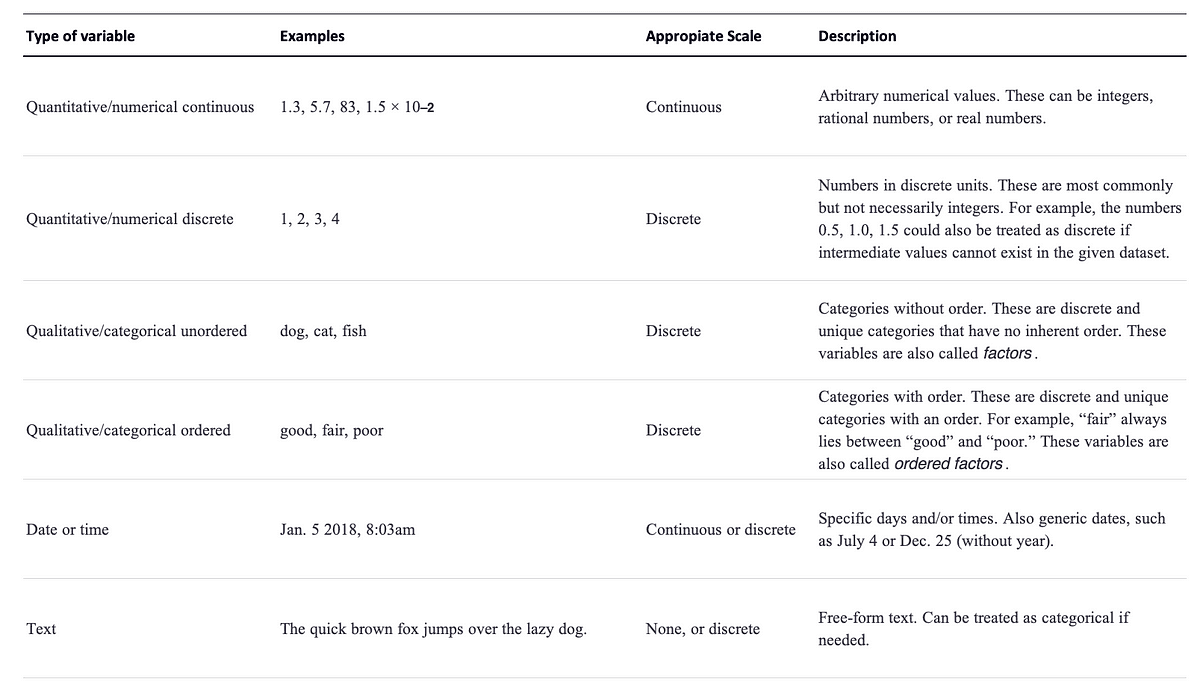
图片由作者提供。分类摘自 O'Reilly 的数据可视化基础。
一旦我们明确了我们拥有什么样的数据,我们就需要了解如何将这些数据编码到最终图表中。
2. 编码信息:视觉词典
可视化编码是数据可视化的核心。它将抽象的数字翻译成图形表示,这是我们都很流利的语言。
尽管有许多不同类型的数据可视化,乍一看,散点图、饼图和热图似乎没有太多共同之处,但所有这些可视化都可以用一种通用语言来描述,该语言捕获数据值如何转换为纸上的墨迹或屏幕上的彩色像素。
但。。。正如您已经必须意识到的那样...
有数千种编码数字的方法!
主要有两组:
- 视网膜编码:从形状、大小、颜色和强度来看,这些都是我们眼睛立即捕捉到的元素。 它们是元素固有的。
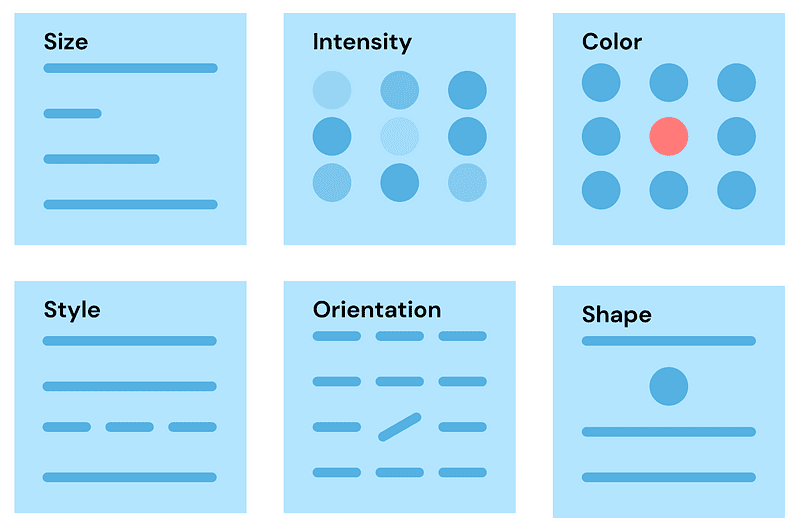
图片来源:作者
- 空间编码: 它们利用我们大脑皮层的空间意识来编码信息。这种编码可以通过比例中的位置、定义的顺序或使用相对大小来实现。

图片来源:作者
有了前面解释的所有编码,我们可以在一个图表中使用所有这些编码,但读者很难快速掌握所有信息。使用多个编码重载图表可能会造成混淆,因此每个图表 1 或 2 个视网膜编码是最佳的。
永远记住,少即是多,所以总是尝试创建极简主义和易于理解的图表。
把它想象成调味一道菜——撒上盐和胡椒可能会增强它,但倒入整个盐瓶可能会破坏味道。
所以现在...应该选择哪种编码?
我的朋友们,这取决于你想编织的故事。
所以你最好问问...
什么有效,什么无效?
虽然我们可以使用的视觉武器库非常庞大,但并非所有武器都适合每场战斗。
考虑哪种编码最适合哪种变量。
- 连续数据变量(如体重和身高)可在通用秤上找到最佳表示形式。
- 离散的,如性别或国籍,在用颜色或空间区域描绘时会发光。
某些图表的直观性背后有一些原因。它们背后有两个主要理论。
1. 格式塔理论
使用技术的人有时会忘记事物的人性方面。格式塔原则是心理学的规则,解释了我们的大脑如何看待模式。
其中一些规则有助于我们理解为什么我们将看起来相似的事物分组或注意到突出的事物。
- 相似: 格式塔相似性意味着我们的大脑将看起来相似的事物分组。这可能是因为它们的位置、形状、颜色或大小。这广泛用于热图或散点图。

图片来源:作者
- 关闭: 边框内的对象(如线条或共享颜色)看起来就像它们属于一起。这使它们从我们看到的其他事物中脱颖而出。我们经常在表格和图形中使用边框或颜色对数据进行分组。

图片来源:作者
- 连续性: 当单个元素连接在一起时,我们的眼睛认为它们属于一起。即使他们看起来不同,这条线也让我们把他们视为一个群体。这在折线图中被广泛使用。
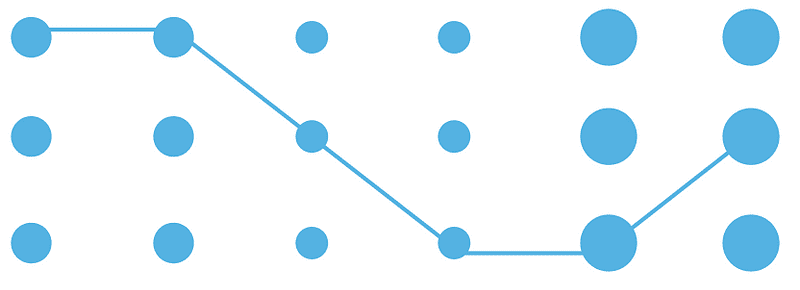
图片来源:作者
- 接近: 我们认为,如果事物彼此接近,它们就属于同一组。为了表明事物属于一起,请将它们放在一起。使用一点空间可以帮助分隔不同的组。这通常用于散点图或节点链接图。
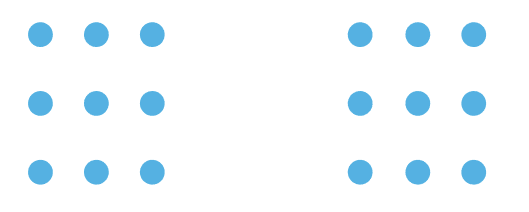
图片来源:作者
因此,在进行可视化时,格式塔原则及其相互作用非常重要。
2.比例油墨的原理
在许多不同的可视化场景中,我们通过图形元素的范围来表示数据值。
通常的做法是使用单词墨迹来指代可视化效果中偏离背景颜色的任何部分。这包括线条、条形、点、共享区域和文本。
例如,在条形图中,我们绘制从 0 开始并以它们表示的数据值结束的条形。在这种情况下,数据值不仅编码在柱线的端点中,而且还编码在柱线的高度或长度中。
如果我们绘制的柱线以不同于 0 的值开始,那么柱线的长度和柱线端点将传达相互矛盾的信息。
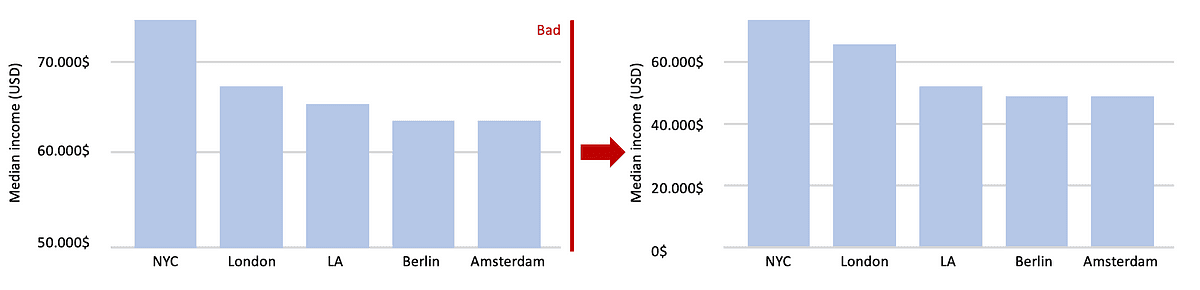
图片来源:作者
在所有这些情况下,我们需要确保没有不一致。这个概念被伯格斯特罗姆和韦斯特称为比例墨水原理。
“当阴影区域用于表示数值时,该阴影区域的面积应与相应的值成正比。
在试图操纵数据时,违反这一原则的情况很常见,尤其是在大众媒体和金融界。
每当我们使用图形元素(例如矩形、任意形状的阴影区域)或任何其他具有已定义视觉范围的元素(可能与显示的数据值一致或不一致)时,都会发生类似的问题。
良好可视化的本质
美学和功能之间的惊人平衡至关重要。严格遵守伯格斯特罗姆的比例墨水等原则,但不以牺牲可读性为代价。
虽然有些编码可能看起来不太有效,但可以故意选择它们来表达或唤起情感。
在我们这个数据流不断增加的时代,制作有意义的视觉叙事的重要性怎么强调都不为过。尤其是在尝试将我们的见解传达给非数据专业人员时。
良好的数据可视化不仅仅是呈现数字,而是试图围绕故事阐明我们的数据。在讲故事的同时使我们的数据栩栩如生,并在原始信息与现实世界的影响和见解之间建立联系。
作为技术专家和数据爱好者,它是我们的艺术,我们的语言,也是我们与整个世界的桥梁。
由3D建模学习工作室 整理翻译,转载请注明出处!