构建上下文感知聊天机器人:利用 LangChain 框架进行 ChatGPT
在当今快节奏的数字环境中,随着大型语言模型(LLM)的兴起,会话应用程序获得了极大的普及。聊天机器人改变了我们在日常生活中与应用程序、网站甚至客户服务渠道互动的方式。
在线工具推荐:3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器
构建自己的聊天机器人的能力已成为游戏规则的改变者,使企业和个人能够创建个性化、高效且引人入胜的对话界面,以满足他们的特定需求。
本文旨在分解如何利用LLM的强大功能在Python中构建聊天机器人。我们将探索如何使用 ChatGPT 创建我们自己的聊天机器人,以及如何使用流行的 LangChain 框架进一步优化它。
范围和目标
本文涵盖了开发优化聊天机器人的所有关键方面,该聊天机器人使用 ChatGPT 作为下面的模型。我们将使用同时安装了库的Jupyter Notebook。您可以在此工作区中进行操作。openailangchain
在以下部分中,我们将探讨如何使用 OpenAI API 对 ChatGPT 进行基本 API 调用,作为我们对话的构建块。此外,我们将使用基本的 Python 结构为我们的聊天机器人实现上下文感知。最后,我们将使用 LangChain 优化聊天机器人实现和对话历史记录,并探索其内存功能。
基本聊天 API 调用
我们将使用 ChatGPT 作为聊天机器人背后的模型。出于这个原因,我们的第一个动手任务将包括编写一个简单而完整的 API 调用 ChatGPT,以便我们可以建立第一个交互。
以下 Python 函数仅使用库嵌入了我们对 ChatGPT 的所需 API 调用。openai

请注意,在这种情况下,我们正在使用该模型,因为它是最强大的 GPT-3.5 模型,并且针对聊天进行了优化,也是最便宜的模型之一。有关可用不同模型的更多信息,请参阅 OpenAI 文档。gpt-3.5-turbo
您是否需要帮助获取 OpenAI API 密钥?然后,培训入门OpenAI API和ChatGPT适合您。
让我们一步一步地分析我们的实现!
该函数是创建聊天完成请求的原始 OpenAI 函数调用的包装器。chatgpt_call()ChatCompletion.create
给定所需的提示,该函数会报告相应的 ChatGPT 完成。若要成功完成调用,只需提供要使用的模型的 ID () 和所需的提示 ()。modelprompt
ChatGPT 返回的实际完成包含元数据以及响应本身。然而,完成本身总是在现场返回。有关完整完成内容的更多信息,请参阅 OpenAI 文档。response.choices[0].message[“content”]
鉴于此实现,我们可以简单地在一行中提示 ChatGPT:
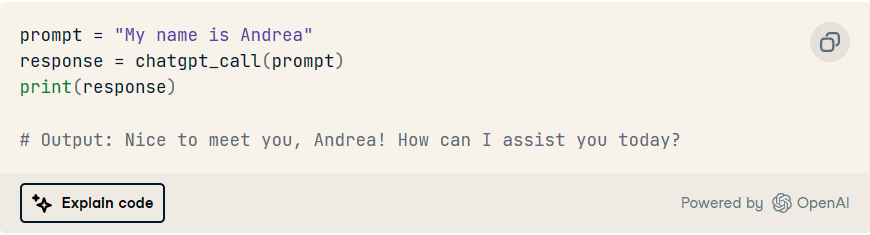
作为独立交互的调用
您是否注意到上述实现中的任何问题?
为了给你一个提示,让我们做一个后续的互动:
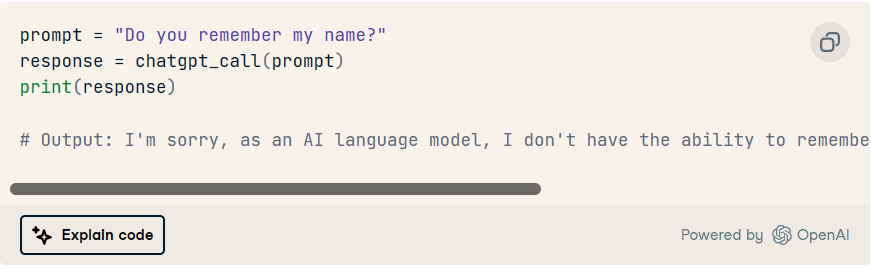
是的,正如我们可以观察到的,每个 API 调用都是一个独立的交互。这意味着模型没有先前输入提示或已完成的记忆。每次调用该函数时,我们都会开始一个全新的对话。chatgpt_call()
在尝试构建聊天机器人时,这绝对是一个问题,因为如果它不记得我们到目前为止一直在讨论的内容,就不可能与我们的模型进行对话。出于这个原因,我们的下一步是让模型知道我们之前的交互。
情境感知
上下文感知使聊天机器人能够根据正在进行的对话理解并做出适当的响应。
通过建立上下文,可以根据过去的交互来个性化未来的交互,保持对话的连续性并避免重复。此外,通过上下文感知聊天机器人,用户可以主动提出澄清问题或提供建议以纠正误解。
总体而言,上下文感知增强了聊天机器人的自然性、有效性和用户体验。从现在开始,我们将以前的交互集合称为对话历史记录或记忆。
用于 ChatGPT 的原始 OpenAI API 已经提供了一种将我们的对话历史记录与每个新提示一起发送到模型的方法。此外,LangChain 框架还提供了一种更有效、更优化地管理 ChatGPT 内存的方法。
了解系统、助手和用户消息
ChatGPT 的对话历史结构
此时,我们可以通过提供所需的提示直接使用该方法。如果我们仔细观察实现,输入提示被格式化为列表的一部分。此列表实际上旨在跟踪对话历史记录,这就是为什么必须以非常特殊的方式格式化它的原因。chatgpt_call()messages
让我们仔细看看!
到目前为止,我们已将消息列表格式化如下:chatgpt_call()

该列表将对话历史记录存储为字典集合。列表中的每个字典使用两个键值对表示会话中的一条消息。messages
- 带有值的键指示消息已由用户发送。
roleuser - 具有值的键包含实际的用户提示。
contentprompt
这是一个非常简单的示例,只包含一个交互。尽管密钥将始终存储用户提示或聊天机器人的完成,但该密钥的通用性要广泛得多。contentrole
系统、助理和用户角色
该项指示 中消息的所有者。使用 ChatGPT 时,我们最多可以有三个角色:rolecontent
- 用户。正如我们已经讨论过的,该角色对应于与聊天机器人交互的实际用户。
user - 助理。该角色对应于聊天机器人。
assistant - 系统。该角色用于为聊天机器人提供说明、指导和上下文。系统消息有助于指导用户交互、设置聊天机器人行为、提供上下文信息以及处理对话中的特定交互。系统消息可以被视为聊天机器人的高级指令,对用户透明。
system
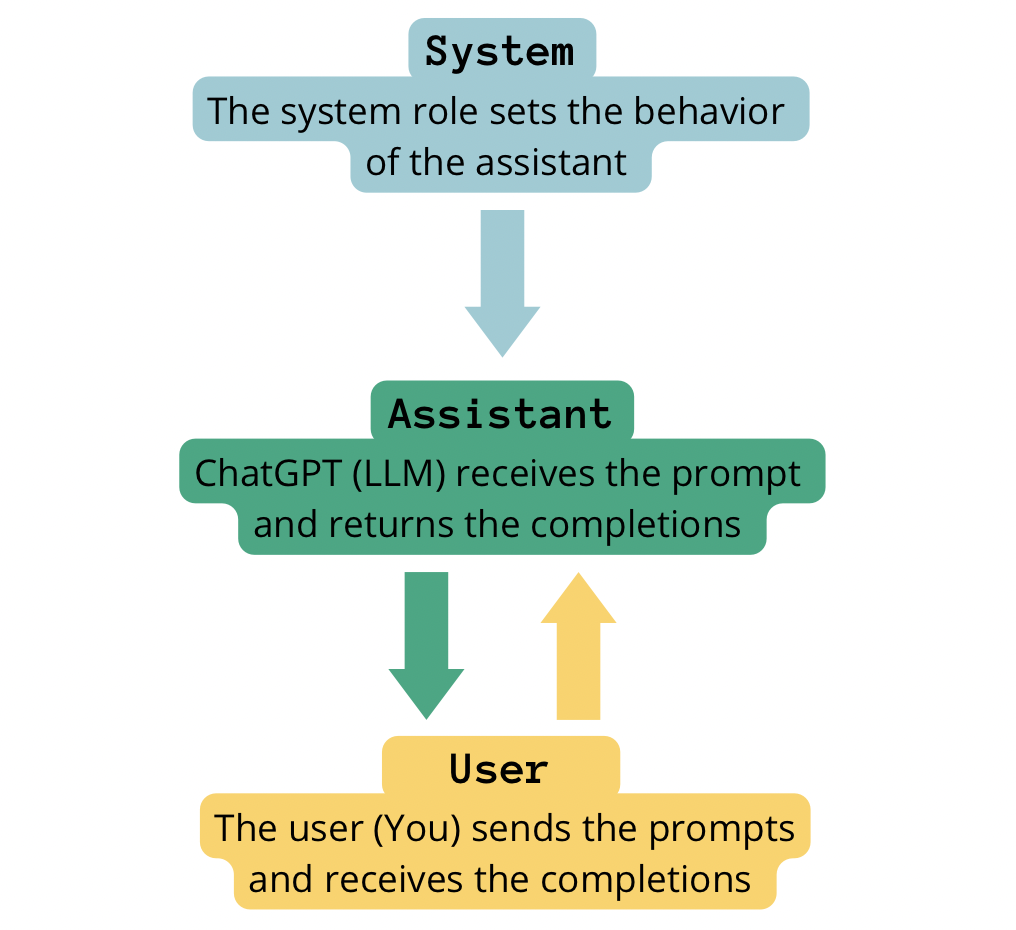
自制形象。使用 chatGPT 构建聊天机器人时对话链中不同角色的交互。
构建对话历史记录
我们可以继续利用列表中的三个 、 和角色来构建我们的对话历史记录。userassistantsystemmessages
鉴于我们的测试交互,使用上述三个角色的正确格式的对话历史记录可能如下所示:
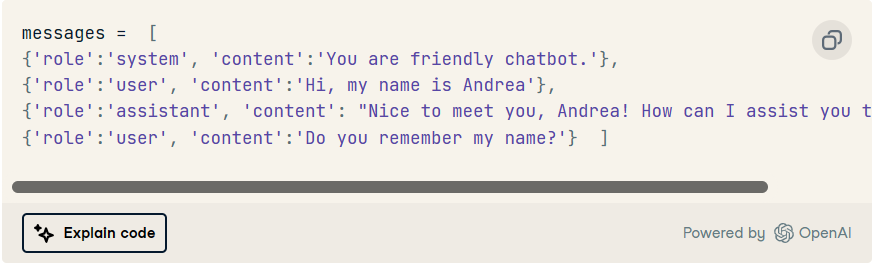
我们可以稍微修改我们的函数,将对话历史作为输入参数包含在内:call_chatgpt()

让我们尝试这个新的实现!
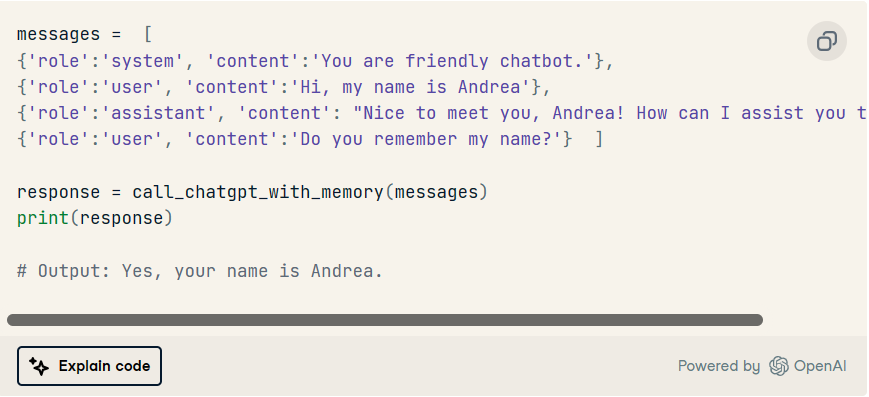
好! 我们已经设法让模型了解我们过去的交互,以便我们可以实际与模型进行对话。尽管如此,我们需要找到一种方法来自动更新我们的列表。messages
自动对话历史记录
我们可以通过进一步阐述我们的 API 调用函数来实现消息的自动收集:

让我们现在试试吧!
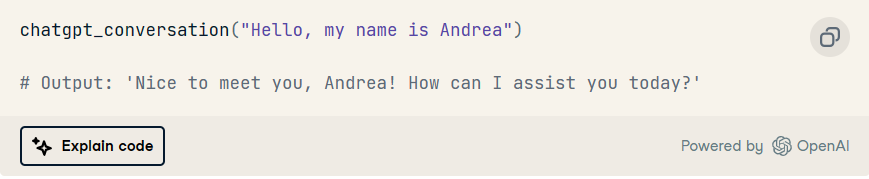
以及后续互动:
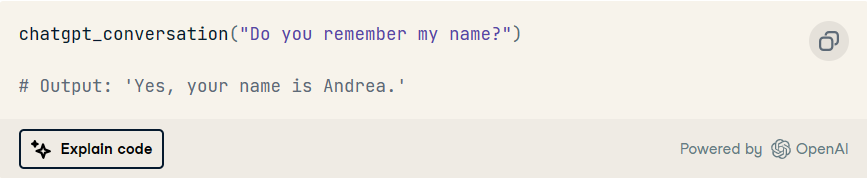
现在,对话历史记录会自动更新。最后,请注意,只需打印列表即可随时观察对话历史记录及其结构。messages
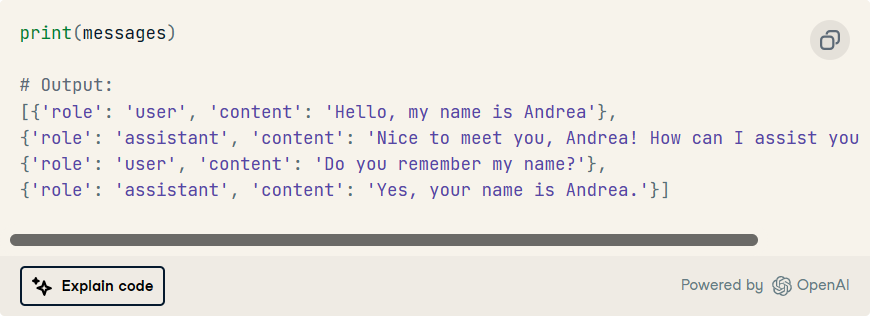
语言链框架
到目前为止,我们会同意我们的实现导致了一个有用的聊天机器人,但它可能不是它最优化的版本。
不断提供每个先前的提示和完成消息可以快速导致大量的令牌集合,ChatGPT 需要在返回最新完成之前处理所有这些令牌。
到目前为止,我们已经使用操作将过去的交互捆绑在一起,以便聊天机器人具有某种记忆。尽管如此,内存管理可以通过使用专用包(如 LangChain)以更有效的方式完成。.append
LangChain是一个用于开发由语言模型驱动的应用程序的框架。作为当今最受欢迎的应用程序之一的聊天机器人,LangChain 为构建聊天机器人对话历史记录提供了更清晰的实现,以及其他更有效地处理它的替代方案。
有关 LangChain 框架本身的更多信息,我强烈推荐介绍性文章 LangChain for Data Engineering & Data Applications。
与LangChain的简单对话历史
在本节中,我们将探讨如何使用 LangChain 框架来构建聊天机器人。
该库可以替代上面使用的库,因为该模块已经允许您通过两行简单的代码与 ChatGPT 进行交互:langchainopenailangchain.llms
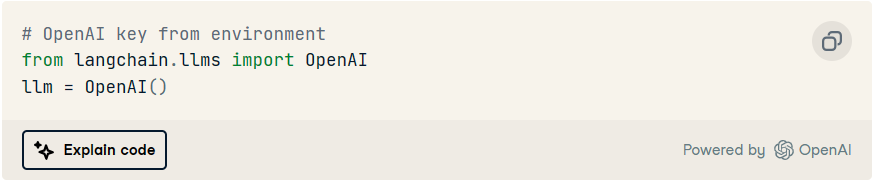
加载模型后,让我们导入将存储对话历史记录的内存对象。为了存储过去与聊天机器人的每次交互,LangChain提供了所谓的:llmConversationBufferMemory

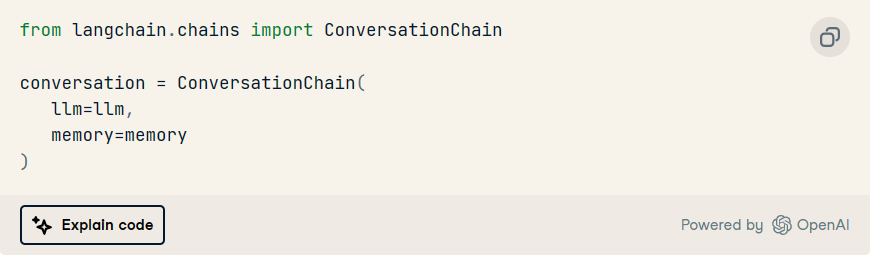
现在终于到了导入所谓的 的时候了,作为一个包装器,它将利用 和 将用户提示提供给 ChatGPT 并返回其完成:ConversationChainllmmemory
最后,要向 ChatGPT 提交用户提示,我们可以使用以下方法:.predict
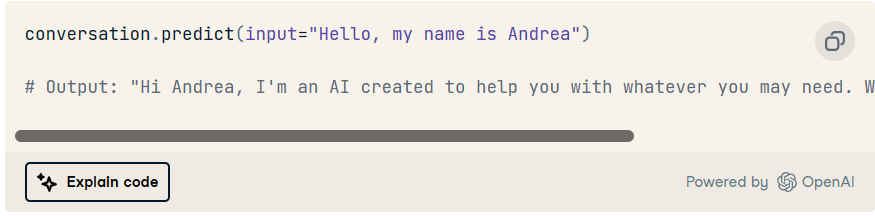
让我们设置观察模型认为提供完成的信息。让我们在后续交互中尝试一下:verbose=True
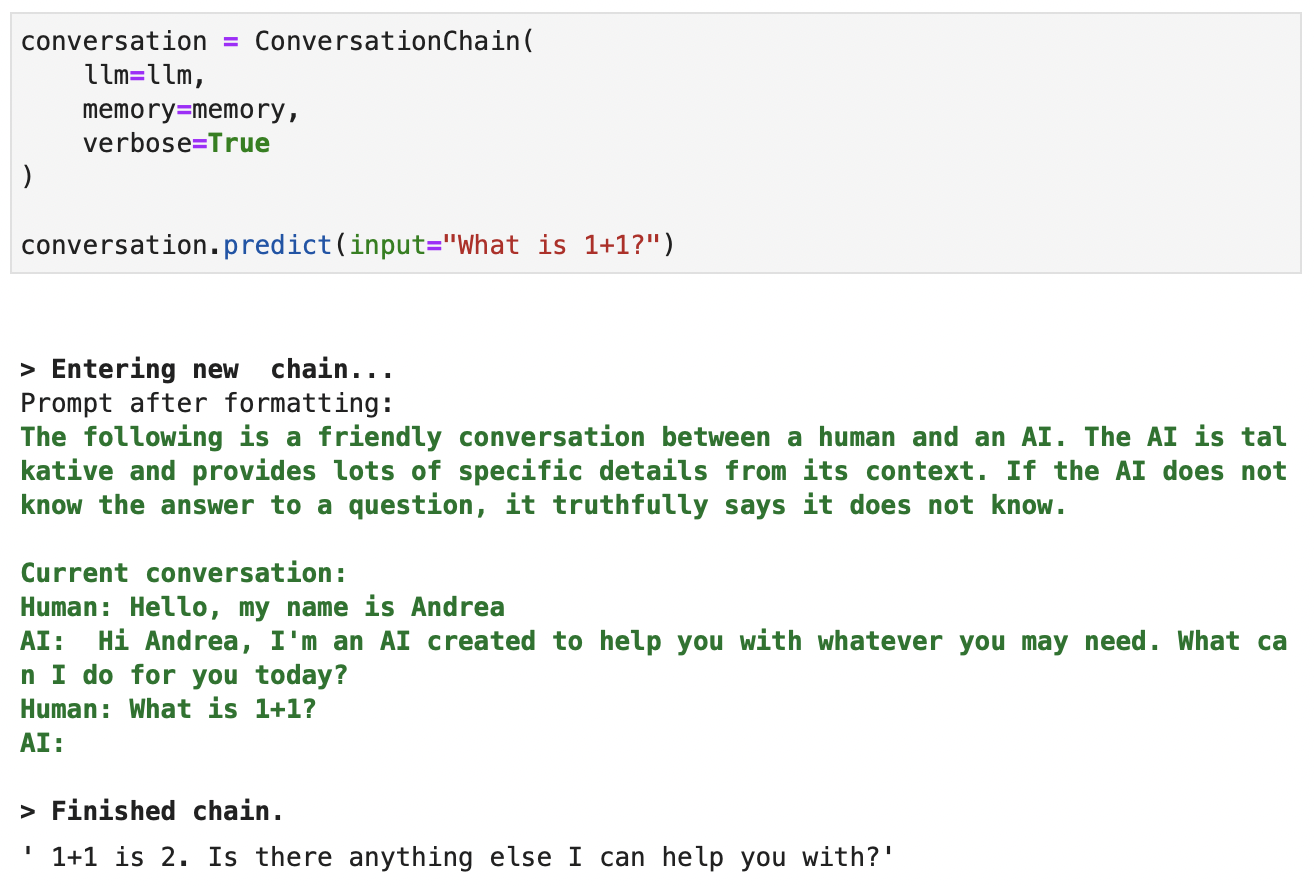
创建完成时可用于 ChatGPT 的上下文的屏幕截图。绿色的详细输出。
最后,让我们检查一下它是否完全记住了以前的交互:
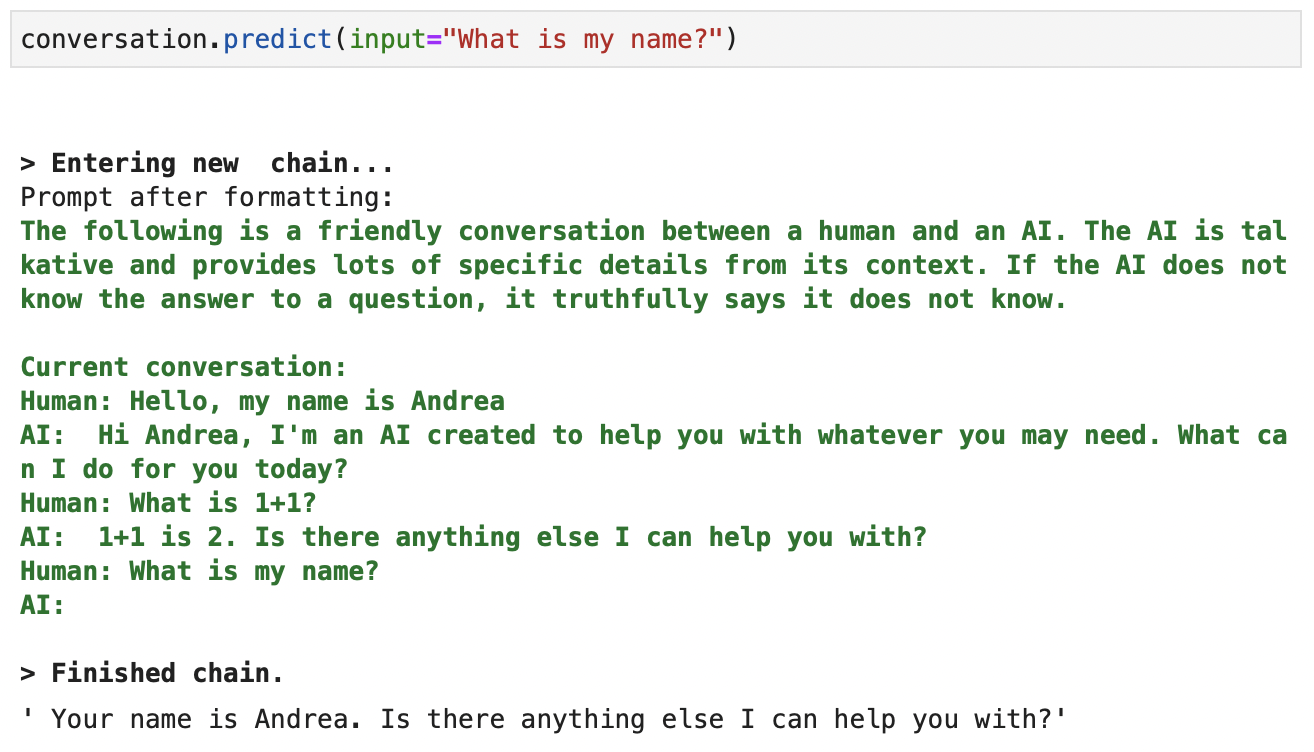
创建完成时可用于 ChatGPT 的上下文的屏幕截图。绿色的详细输出。
填写对话历史记录
我们可以使用方法向聊天机器人提供额外的上下文。这样,我们可以让我们的聊天机器人知道任何想要的内容,而无需在对话中提供这些信息。在 LangChain 中,用于此目的的关键字是 和 。例如memory.save_context()inputoutput

此外,我们还可以随时通过运行或.print(memory.buffer)memory.load_memory_variables({})
语言链内存类型
LangChain为ChatGPT实现了不同类型的内存。上面使用的内容跟踪与 ChatGPT 的每一次交互。尽管如此,我们已经讨论过,提示 ChatGPT 与整个对话历史记录可以迅速升级到大量令牌,以便在每次新交互时进行处理。ConversationBufferMemory
请记住,除了 ChatGPT 对每次交互有令牌限制这一事实之外,其使用成本还取决于令牌的数量。随着时间的推移,处理每个新交互中的所有对话历史记录可能会很昂贵。
为了避免对话历史的连续处理,LangChain 实现了其他优化的方式来管理 ChatGPT 的内存。我们将在下一节中探讨最先进的类型之一。
与LangChain的高级对话历史记录
一种管理内存的高级方法避免存储每个过去的交互,包括存储交互的摘要。
这种类型的内存是我最喜欢的一种,因为它可以真正优化内存管理,而不会牺牲任何过去的交互。
我们去吧!
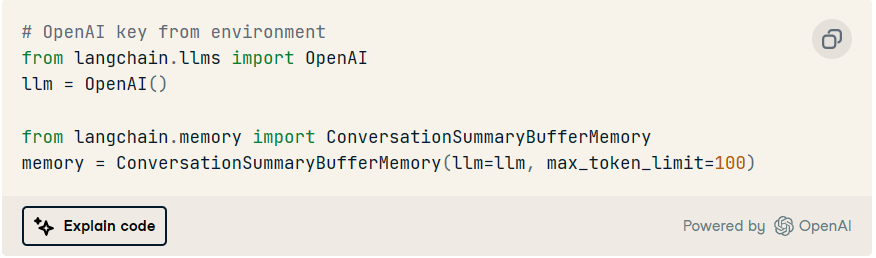
请注意,这种类型的内存使用定义的来生成先前交互的摘要。llm
此外,此内存可以存储最多最大数量的令牌 () 的完整交互。超过此限制,它将这些消息的信息合并到摘要中。max_token_limit
为了测试它,让我们创建一个与大量代币的交互。考虑以下几点:schedule
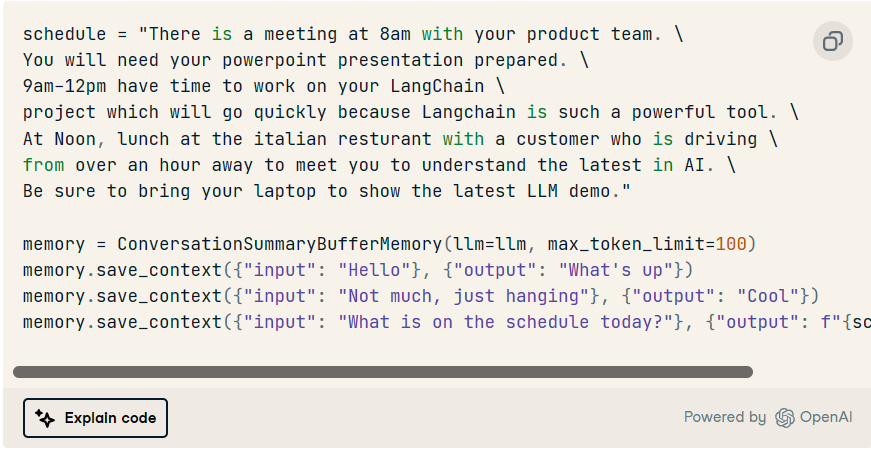
现在,我们只需要声明一个新的对话链,给定前面示例中的 和 。llmmemory
我们可以使用提示 ChatGPT:.predict
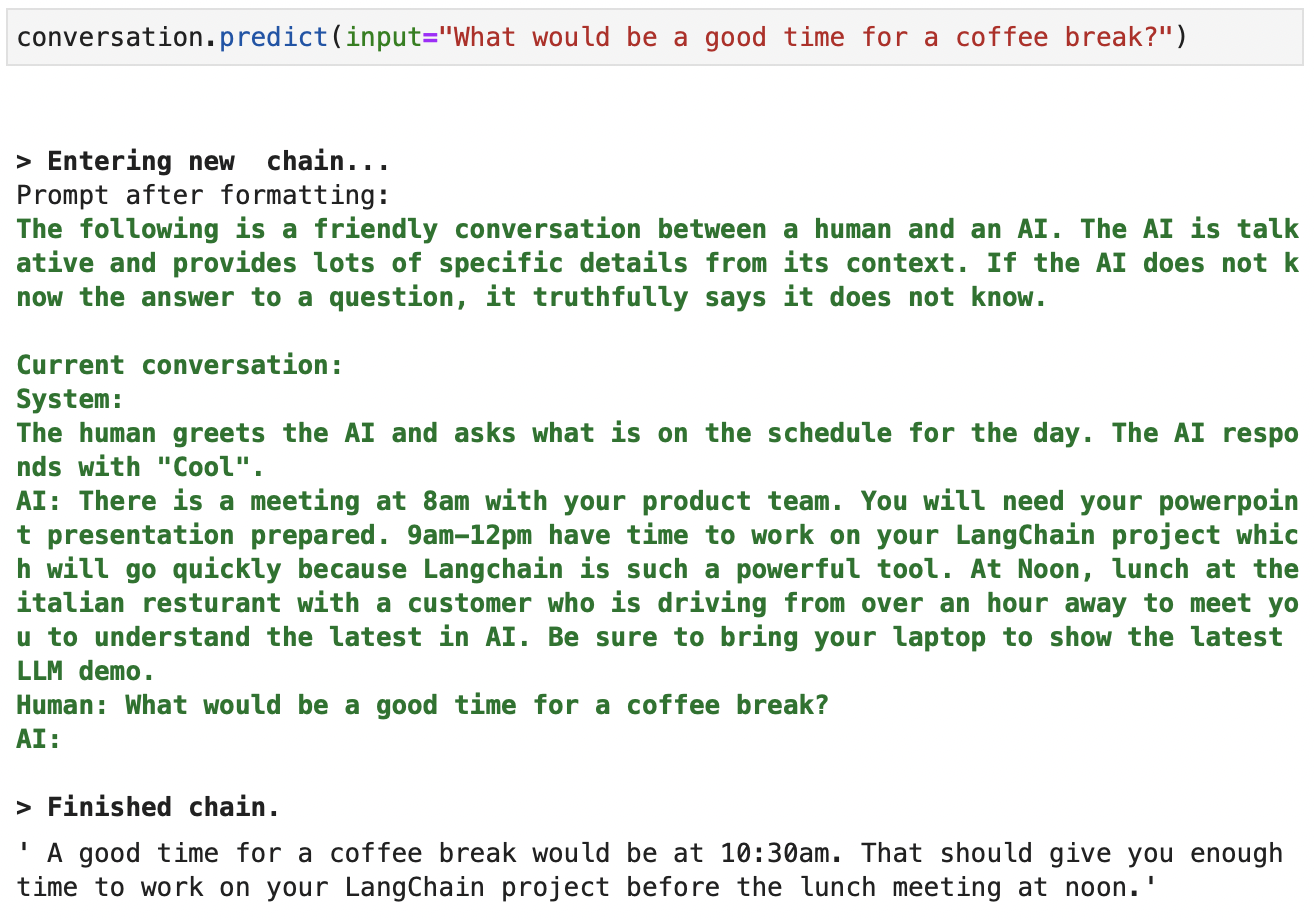
创建完成时可用于 ChatGPT 的上下文的屏幕截图。绿色的详细输出。
正如我们所观察到的,聊天机器人会保留原始对话历史记录的摘要,从而减少 ChatGPT 在每次后续交互中处理的令牌数量。
就是这样!现在我们可以继续与我们优化的聊天机器人交谈数小时!
设置 ,以便在笔记本中获得更愉快的问答体验。verbose=False
结论
在本文中,我们已经了解了如何使用众所周知的 ChatGPT 模型构建上下文感知聊天机器人。
我们已经看到了如何构建我们自己的上下文感知聊天机器人可以导致持续的交互。这种迭代方法促进了持续的反馈循环,使您能够在对话过程中保持用户的需求和偏好。
我们已经看到了管理聊天机器人对话历史记录的两种主要方法。首先,通过使用原始的 ChatGPT API 导致功能性原生聊天机器人。其次,通过使用专用的LangChain框架和优化的内存类型实现。
由3D建模学习工作室 整理翻译,转载请注明出处!