在 Python 中应用描述性和推理性统计
统计学是一个涵盖从收集数据和数据分析到数据解释的活动的领域。这是一个研究领域,可帮助相关方在面临不确定性时做出决定。

推荐:使用NSDT编辑器快速搭建3D应用场景
统计领域的两个主要分支是描述性和推理性。描述性统计是使用各种方式(例如汇总统计、可视化和表格)与数据汇总相关的分支。而推论统计更多的是基于数据样本的人口泛化。
本文将通过 Python 示例介绍描述性和推理统计中的一些重要概念。让我们进入它。
描述统计学
正如我之前提到的,描述性统计侧重于数据汇总。这是将原始数据处理成有意义信息的科学。可以使用图形、表格或汇总统计来执行描述性统计。但是,汇总统计是进行描述性统计的最流行方法,因此我们将重点关注此。
对于我们的示例,我们将使用以下数据集示例。
import pandas as pd
import numpy as np
import seaborn as sns
tips = sns.load_dataset('tips')
tips.head()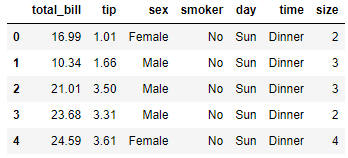
有了这些数据,我们将探索描述性统计。在汇总统计中,有两种最常用的:集中趋势度量和传播度量。
集中趋势的度量
集中趋势是数据分布或数据集的中心。集中趋势的度量是获取或描述我们数据的中心分布的活动。集中趋势的度量将给出一个定义数据中心位置的单一值。
在集中趋势的度量中,有三种流行的度量:
1. 平均值
平均值或平均值是一种生成代表数据最常见值的奇异值输出的方法。但是,平均值不一定是在我们的数据中观察到的值。
我们可以通过取数据中现有值的总和并将其除以值的数量来计算平均值。我们可以用以下等式表示平均值:
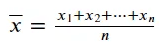
图片来源:作者
在 Python 中,我们可以使用以下代码计算数据平均值。
round(tips['tip'].mean(), 3)2.998使用 pandas 系列属性,我们可以获得数据均值。我们还对数据进行舍入,使数据读取更容易。
均值作为集中趋势的度量有一个缺点,因为它受到异常值的严重影响,这可能会扭曲汇总统计量,并且不能最好地代表实际情况。在偏斜的情况下,我们可以使用中位数。
2. 中位数
如果我们对数据进行排序,中位数是位于数据中间的奇异值,代表数据的中间点位置 (50%)。作为集中趋势的度量,当数据偏斜时,中位数更可取,因为它可以代表数据中心,因为异常值或偏斜值不会强烈影响它。
中位数是通过按升序排列所有数据值并找到中间值来计算的。中位数是奇数个数据值的中间值,但中位数是偶数个数据值的两个中间值的平均值。
我们可以使用以下代码用 Python 计算中位数。
tips['tip'].median()2.93. 模式
模式是数据中出现频率最高或出现次数最多的值。数据可以具有单模式(单峰)、多个模式(多模式)或根本没有模式(如果没有重复值)。
模式通常用于分类数据,但也可用于数值数据。但是,对于分类数据,它可能只使用模式。这是因为分类数据没有任何数值来计算平均值和中位数。
我们可以使用以下代码计算数据模式。
tips['day'].mode()
结果是具有分类类型值的系列对象。“Sat”值是唯一出现的值,因为它是数据模式。
传播措施
散布(或变异性、离散)度量是描述数据值分布的度量。测量提供了有关数据值在数据集中如何变化的信息。它通常与集中趋势的度量一起使用,因为它们补充了整体数据信息。
价差的度量也有助于理解我们对集中趋势输出的度量。例如,较高的数据分布可能表示观测数据之间存在显著偏差,并且数据均值可能无法最好地表示数据。
以下是使用的各种传播措施。
- 范围
范围是数据最大值(最大值)和最小值(最小值)之间的差值。这是最直接的测量,因为信息仅使用数据的两个方面。
使用可能会受到限制,因为它不能说明太多关于数据分布的信息,但如果我们有一定的阈值用于数据,它可能有助于我们的假设。让我们尝试使用 Python 计算数据范围。
tips['tip'].max() - tips['tip'].min()9.02. 方差
方差是一种点差度量,它根据数据平均值通知我们的数据点差。我们通过将每个值的差值与数据均值的差值平方并将其除以数据值的数量来计算方差。由于我们通常使用数据样本而不是总体,因此我们将数据值的数量减去 1。样本方差方程如下图所示。
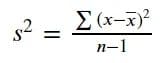
图片来源:作者
方差可以解释为一个值,指示数据向均值和彼此的分布程度。方差越高意味着数据分布越广。但是,方差计算对异常值很敏感,因为我们对分数与平均值的偏差进行了平方;这意味着我们对异常值给予了更多的权重。
让我们尝试用 Python 计算数据方差。
round(tips['tip'].var(),3)1.914上述方差可能表明我们的数据方差很大,但我们可能希望使用标准差来获得数据扩散测量的实际值。
3. 标准差
标准差是衡量数据分布的最常用方法,它是通过取方差的平方根来计算的。
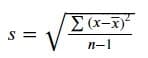
图片来源:作者
方差和标准差之间的差异在于其值给出的信息。方差值仅表示我们的值与平均值的分布程度,并且当我们对原始值进行平方时,方差单位与原始值不同。但是,标准差值与原始数据值是相同的单位,这意味着标准差值可以直接用于衡量我们数据的传播。
让我们尝试使用以下代码计算标准偏差。
round(tips['tip'].std(),3)1.384标准差最常见的应用之一是估计数据间隔。我们可以使用经验规则或 68–95–99.7 规则来估计数据间隔。经验规则指出,估计 68% 的数据±一个 STD 的数据平均值范围内,95% 的数据是两个 STD ±平均值,99.7% 的数据在三个 STD ±平均值范围内。
4. 四分位距
四分位数间距 (IQR) 是使用第一和第三四分位数数据之间的差异计算的散布度量。四分位数本身是一个将数据分为四个不同部分的值。为了更好地理解,让我们看一下下图。
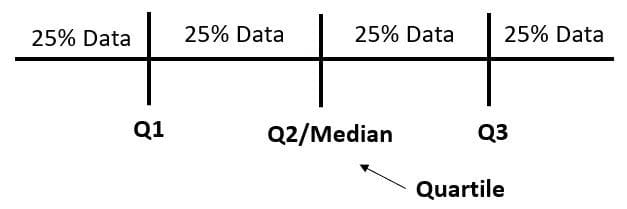
图片来源:作者
四分位数是除以数据的值,而不是除法的结果。我们可以使用以下代码来查找四分位数值和 IQR。
q1, q3= np.percentile(tips['tip'], [25 ,75])
iqr = q3 - q1
print(f'Q1: {q1}\nQ3: {q3}\nIQR: {iqr}')Q1: 2.0
Q3: 3.5625
IQR: 1.5625使用 numpy 百分位数函数,我们可以获取四分位数。通过减去第三个四分位数和第一个四分位数,我们得到 IQR。
IQR 可用于通过获取 IQR 值并计算数据上限/下限来识别数据异常值。上限公式是Q3 + 1.5 * IQR,而下限是Q1 - 1.5 * IQR。任何超过此限制的值都将被视为异常值。
为了更好地理解,我们可以使用箱线图来了解 IQR 异常值检测。
sns.boxplot(tips['tip'])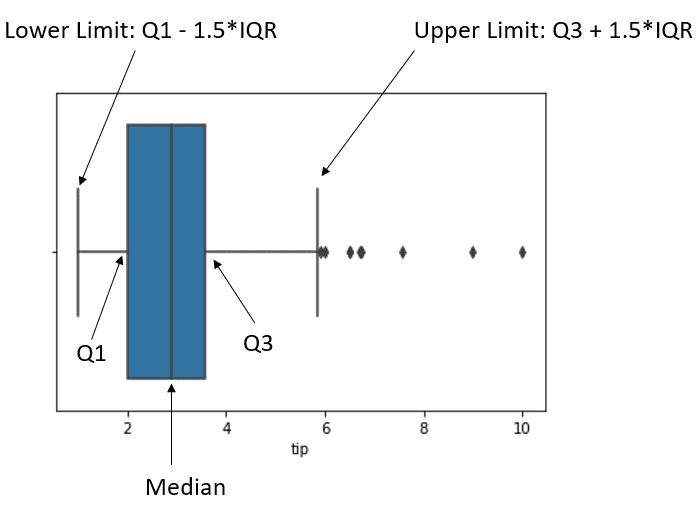
上图显示了数据箱线图和数据位置。上限之后的黑点是我们认为的异常值。
推论统计
推论统计是一个分支,它根据人口信息来自的数据样本来概括人口信息。使用推论统计是因为通常不可能获得整个数据总体,我们需要从数据样本中进行推理。例如,我们想了解印度尼西亚人对人工智能的看法。然而,如果我们调查印度尼西亚人口中的每个人,这项研究将花费太长时间。因此,我们使用代表人口的样本数据,并推断印度尼西亚人口对人工智能的看法。
让我们探索一下我们可以使用的各种推理统计。
1. 标准误差
标准误差是一种推论统计量度量,用于估计给定样本统计量的真实总体参数。标准误差信息是如果我们对来自同一总体的数据样本重复实验,样本统计量将如何变化。
均值的标准误差 (SEM) 是最常用的标准误差类型,因为它告诉均值在给定样本数据的情况下代表总体的程度。要计算 SEM,我们将使用以下等式。
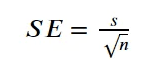
图片来源:作者
平均值的标准误差将使用标准差进行计算。样本数量越多,数据的标准误差就越小,其中较小的 SE 意味着我们的样本非常适合表示数据总体。
要获得平均值的标准误差,我们可以使用以下代码。
from scipy.stats import sem
round(sem(tips['tip']),3)0.089我们经常报告带有数据平均值的 SEM,其中真实平均人口估计落在平均值±SEM 范围内。
data_mean = round(tips['tip'].mean(),3)
data_sem = round(sem(tips['tip']),3)
print(f'The true population mean is estimated to fall within the range of {data_mean+data_sem} to {data_mean-data_sem}')The true population mean is estimated to fall within the range of 3.087 to 2.90900000000000032. 置信区间
置信区间也用于估计真实的总体参数,但它引入了置信水平。置信水平以一定的置信百分比估计真实总体参数范围。
在统计学中,置信度可以描述为概率。例如,置信水平为 90% 的置信区间意味着真实平均总体估计值将在置信区间的上限和下限值 90 次中有 100 次。CI 使用以下公式计算。
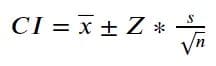
图片来源:作者
上面的公式有一个熟悉的符号,除了 Z。Z 表示法是通过定义置信水平(例如 95%)并使用 z 临界值表确定 z 分数(置信水平为 1% 时为 96.95)获得的 z 分数。此外,如果我们的样本较小或低于 30,我们应该使用 t 分布表。
我们可以使用以下代码来获取带有 Python 的 CI。
import scipy.stats as st
st.norm.interval(confidence=0.95, loc=data_mean, scale=data_sem)(2.8246682963727068, 3.171889080676473)上述结果可以解释为我们的数据真实总体均值介于 2.82 到 3.17 之间,置信水平为 95%。
3. 假设检验
假设检验是推论统计中的一种方法,用于从有关总体的数据样本中得出结论。估计的总体可以是总体参数或概率。
在假设检验中,我们需要有一个称为原假设 (H0) 和备择假设 (Ha) 的假设。原假设和备择假设总是相反的。然后,假设检验过程将使用样本数据来确定是否可以拒绝原假设或我们无法拒绝它(这意味着我们接受备择假设)。
当我们执行假设检验方法以查看是否必须否定原假设时,我们需要确定显著性水平。显著性水平是检验中允许发生的类型 1 错误(当 H0 为真时拒绝 H0)最大概率。通常,显著性水平为 0.05 或 0.01。
为了从样本中得出结论,假设检验在假设原假设为真时使用 P 值来衡量样本结果的可能性。当 P 值小于显著性水平时,我们否定原假设;否则,我们不能拒绝它。
假设检验是一种可以在任何总体参数中执行的方法,也可以对多个参数执行。例如,下面的代码将对两个不同的总体执行 t 检验,以查看此数据是否与另一个明显不同。
st.ttest_ind(tips[tips['sex'] == 'Male']['tip'], tips[tips['sex'] == 'Female']['tip'])Ttest_indResult(statistic=1.387859705421269, pvalue=0.16645623503456755)在t检验中,我们比较两组之间的均值(成对检验)。t 检验的原假设是两组均值之间没有差异,而备择假设是两组均值之间存在差值。
t 检验结果表明,由于 P 值高于 0.05 显著性水平,因此男性和女性之间的小费没有显著差异。这意味着我们未能拒绝原假设并得出结论,即两组均值之间没有差异。
当然,上面的检验只是简化了假设检验的例子。当我们进行假设检验时,我们需要知道很多假设,我们可以做很多测试来满足我们的需求。
结论
我们需要知道统计领域的两个主要分支:描述性统计和推论性统计。描述性统计涉及汇总数据,而推论统计处理数据泛化以对人口进行推断。在本文中,我们讨论了描述性和推理性统计,同时提供了 Python 代码的示例。
由3D建模学习工作室 整理翻译,转载请注明出处!