LlamaIndex:将个人数据添加到LLM
lamaIndex是您构建基于LLM的应用程序的友好数据伙伴。您可以使用自然语言轻松摄取、管理和检索私有和特定于域的数据。
在线工具推荐:3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器
LlamaIndex是基于大型语言模型(LLM)的应用程序的数据框架。像 GPT-4 这样的 LLM 是在大量公共数据集上预先训练的,允许开箱即用的令人难以置信的自然语言处理能力。但是,如果无法访问您自己的私人数据,它们的效用会受到限制。
LlamaIndex 允许您通过灵活的数据连接器从 API、数据库、PDF 等中提取数据。然后,LlamaIndex 允许通过查询引擎、聊天界面和 LLM 支持的数据代理对数据进行自然语言查询和对话。它使您的LLM能够大规模访问和解释私有数据,而无需在较新的数据上重新训练模型。
无论您是寻找一种以自然语言查询数据的简单方法的初学者,还是需要深度自定义的高级用户,LlamaIndex 都能提供这些工具。高级 API 允许仅使用五行代码即可入门,而较低级别的 API 允许完全控制数据摄取、索引、检索等。
LlamaIndex指数如何运作?
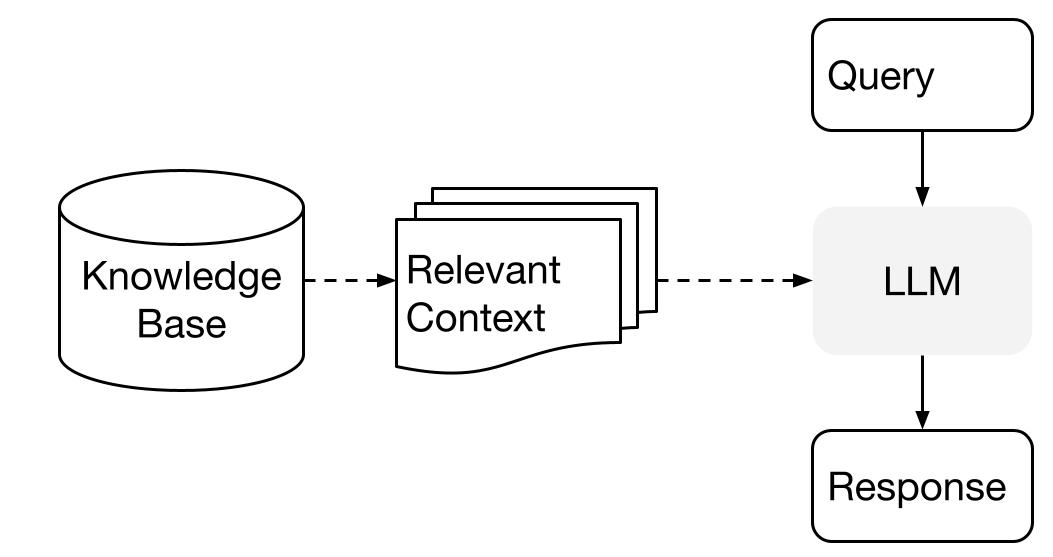
LlamaIndex使用检索增强生成(RAG)系统,该系统将大型语言模型与私有知识库相结合。它通常由两个阶段组成:索引阶段和查询阶段。
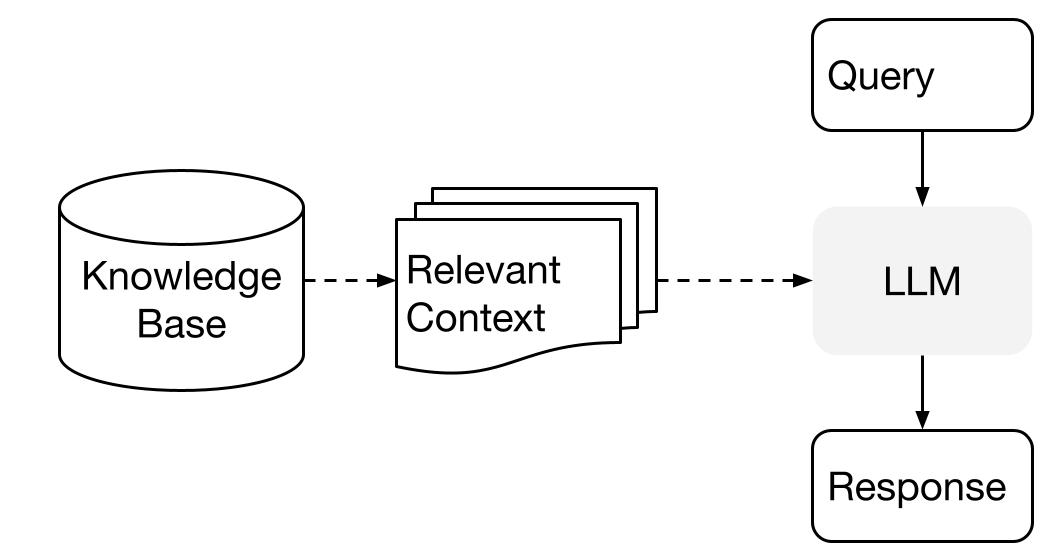
索引阶段
LlamaIndex将在索引阶段有效地将私有数据索引为矢量索引。此步骤有助于创建特定于您的域的可搜索知识库。您可以输入文本文档、数据库记录、知识图谱和其他数据类型。
从本质上讲,索引将数据转换为捕获其语义含义的数字向量或嵌入。它可以跨内容进行快速相似性搜索。
查询阶段
在查询阶段,RAG 管道会根据用户的查询搜索最相关的信息。然后将此信息与查询一起提供给LLM,以创建准确的响应。
此过程允许LLM访问其初始培训中可能未包含的当前和更新信息。
此阶段的主要挑战是对潜在的多个知识库进行检索、组织和推理。
设置LlamaIndex索引
在我们深入研究 LlamaIndex 教程和项目之前,我们必须安装 Python 包并设置 API。
我们可以简单地使用 pip 安装 LlamaIndex。

默认情况下,LlamaIndex使用OpenAI GPT-3 text-davinci-003模型。若要使用此模型,必须具有设置。您可以通过登录OpenAI的新API令牌创建一个免费帐户并获取API密钥。OPENAI_API_KEY

此外,请确保您已安装该软件包。openai

使用LlamaIndex将个人数据添加到LLM
在本节中,我们将学习使用LlamaIndex来创建简历阅读器。您可以通过转到LinkedIn个人资料页面,单击“更多”,然后单击“保存到PDF”来下载简历。
请注意,我们使用 DataCamp 工作区来运行 Python 代码。可以在“LlamaIndex:将个人数据添加到LLM”工作区中访问所有相关代码和输出。
在运行任何内容之前,我们必须安装 、 和 。我们正在安装,以便我们可以读取和转换PDF文件。llama-indexopenaipypdfpypdf

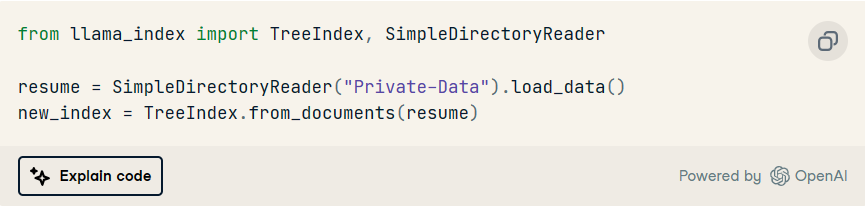
我们有一个名为“Private-Data”的目录,只包含一个PDF文件。我们将使用 来读取它,然后使用 .SimpleDirectoryReaderTreeIndex
为数据编制索引后,可以使用 开始提问。此功能使您能够询问有关文档中特定信息的问题,并在 OpenAI 模型的帮助下收到相应的响应。as_query_engine()GPT-3 text-davinci-003
注意:您可以在DataCamp Workspace中设置OpenAI API,方法是按照使用GPT-3.5和GPT-4通过Python中的OpenAI API教程进行操作。
正如我们所看到的,LLM模型已经准确地响应了查询。它搜索了索引并找到了相关信息。


我们可以进一步询问认证。LlamaIndex似乎已经对候选人有了完整的了解,这对于寻求特定个人的公司来说是有利的。
response = query_engine.query("What is the name of certification that Abid received?")print(response)

创建索引是一个耗时的过程。我们可以通过保存上下文来避免重新创建索引。默认情况下,以下命令会将索引存储保存在目录中。./storage
new_index.storage_context.persist() OpenAI
完成后,我们可以快速加载存储上下文并创建索引。
为了验证它是否正常运行,我们将向查询引擎询问简历中的问题。看来我们已经成功加载了上下文。


聊天机器人
除了问答,我们还可以使用LlamaIndex创建一个个人聊天机器人。我们只需要用函数初始化索引。as_chat_engine()
我们将问一个简单的问题。


在不提供额外背景的情况下,我们将提出后续问题。

In 2021, Abid worked as a Data Science Consultant for Guidepoint, a Writer for Towards Data Science and Towards AI, a Technical Writer for Machine Learning Mastery, an Ambassador for Deepnote, and a Technical Writer for Start It Up.
很明显,聊天引擎运行完美。
构建语言应用程序后,时间轴上的下一步是了解在云中使用大型语言模型 (LLM) 与在本地运行它们的优缺点。这将帮助您确定哪种方法最适合您的需求。
使用 LlamaIndex 构建 Wiki 文本到语音
我们的下一个项目涉及开发一个应用程序,该应用程序可以响应来自维基百科的问题并将其转换为语音。
代码源和其他信息可在以下 DataCamp 工作区中找到。
网页抓取维基百科页面
首先,我们将从意大利 - 维基百科网页中抓取数据并将其保存为文件夹中的文件。italy_text.txtdata

加载数据并构建索引
接下来,我们需要安装必要的软件包。该软件包允许我们使用 API 轻松地将文本转换为语音。elevenlabs

通过使用,我们将加载数据并使用 将 TXT 文件转换为矢量存储。SimpleDirectoryReaderVectorStoreIndex
查询
我们的计划是询问有关该国的一般问题,并收到LLM的答复。query_engine

文本转语音
之后,我们将使用该模块访问 ElevenLabsTTS api。您需要提供 ElevenLabs API 密钥才能启动音频生成功能。您可以在ElevenLabs网站上免费获得API密钥。llama_index.tts

我们将向函数添加响应以生成自然语音。要收听音频,我们将使用 的函数。generate_audioIPython.displayAudio

这是一个简单的例子。您可以使用多个模块来创建助手(如 Siri),通过解释您的私人数据来回答您的问题。有关更多信息,请参阅骆驼索引文档。
除了LlamaIndex之外,LangChain还允许您构建基于LLM的应用程序。此外,您可以阅读 LangChain 数据工程和数据应用简介,了解您可以使用 LangChain 做什么的概述,包括 LangChain 解决的问题和数据用例示例。
LlamaIndex索引用例
LlamaIndex提供了一个完整的工具包来构建基于语言的应用程序。最重要的是,您可以使用Llama Hub的各种数据加载器和代理工具来开发具有多种功能的复杂应用程序。
您可以使用一个或多个插件数据加载器将自定义数据源连接到LLM。
您还可以使用代理工具集成第三方工具和 API。
简而言之,您可以使用LlamaIndex来构建:
- 文档问答
- 聊天机器人
- 代理
- 结构化数据
- 全栈 Web 应用程序
- 私人设置
要详细了解这些用例,请前往 LlamaIndex 文档。
结论
LlamaIndex 提供了一个强大的工具包,用于构建检索增强生成系统,该系统将大型语言模型的优势与自定义知识库相结合。它支持创建特定于域的数据的索引存储,并在推理过程中利用它来为LLM提供相关上下文以生成高质量的响应。
在本教程中,我们了解了 LlamaIndex 及其工作原理。此外,我们构建了一个简历阅读器和文本到语音转换项目,只有几行 Python 代码。使用 LlamaIndex 创建 LLM 应用程序很简单,它提供了一个庞大的插件库、数据加载器和代理。
要成为一名专业的LLM开发人员,下一个自然步骤是注册Master Large Language Models Concepts课程。本课程将使您全面了解LLM,包括其应用,培训方法,道德考虑和最新研究。
由3D建模学习工作室 整理翻译,转载请注明出处!